Constitutional AI: RLHF On Steroids
What Is Constitutional AI?
AIs like GPT-4 go through several different1 types of training. First, they train on giant text corpuses in order to work at all. Later, they go through a process called “reinforcement learning through human feedback” (RLHF) which trains them to be “nice”. RLHF is why they (usually) won’t make up fake answers to your questions, tell you how to make a bomb, or rank all human races from best to worst.
RLHF is hard. The usual method is to make human crowdworkers rate thousands of AI responses as good or bad, then train the AI towards the good answers and away from the bad answers. But having thousands of crowdworkers rate thousands of answers is expensive and time-consuming. And it puts the AI’s ethics in the hands of random crowdworkers. Companies train these crowdworkers in what responses they want, but they’re limited by the crowdworkers’ ability to follow their rules.
In their new preprint Constitutional AI: Harmlessness From AI Feedback, a team at Anthropic (a big AI company) announces a surprising update to this process: what if the AI gives feedback to itself?
Their process goes like this:
-
The AI answers many questions, some of which are potentially harmful, and generates first draft answers.
-
The system shows the AI its first draft answer, along with a prompt saying “rewrite this to be more ethical”.
-
The AI rewrites it to be more ethical.
-
The system repeats this process until it collects a large dataset of first draft answers, and rewritten more-ethical second-draft answers.
-
The system trains the AI to write answers that are less like the first drafts, and more like the second drafts.
It’s called “Constitutional AI” because the prompt in step two can be a sort of constitution for the AI. “Rewrite this to be more ethical” is a very simple example, but you could also say “Rewrite it in accordance with the following principles: [long list of principles].”
Does This Work?
Anthropic says yes:
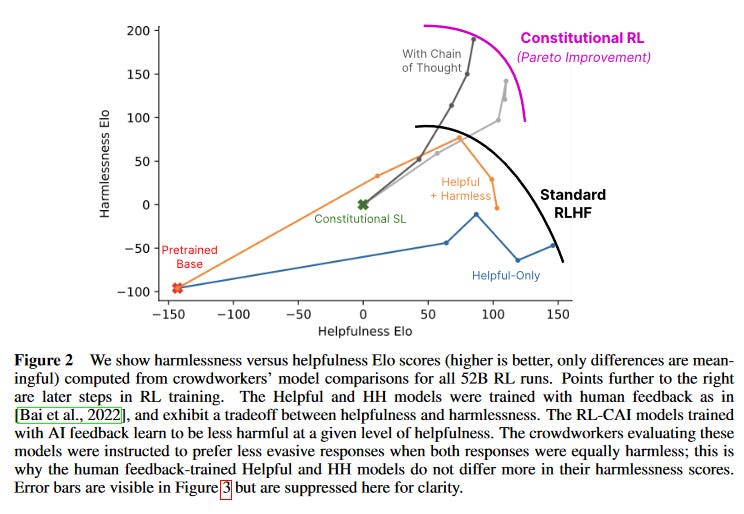
This graph compares the “helpfulness Elo” and “harmlessness Elo” of AIs trained with standard RLHF and Constitutional RL.
Standard practice subdivides ethical AI into “helpfulness” and “harmlessness”. Helpful means it answers questions well. Harmless means it doesn’t do bad or offensive things.
These goals sometimes conflict. An AI can be maximally harmless by refusing to answer any question (and some early models displayed behavior like this). It can be maximally helpful by answering all questions, including “how do I build a bomb?” and “rank all human races from best to worst”. Real AI companies want AIs that balance these two goals and end up along some Pareto frontier; they can’t be more helpful without sacrificing harmlessness, or vice versa.
Here, Anthropic measures helpfulness and harmlessness through Elo, a scoring system originally from chess which measures which of two players wins more often. If AI #1 has helpfulness Elo of 200, and AI #2 has helpfulness Elo of 100, and you ask them both a question, AI #1 should be more helpful 64% of the time.
The graph above shows that constitutionally trained models are “less harmful at a given level of helpfulness”2. This technique isn’t just cheaper and easier to control, it’s also more effective.
Is This Perpetual Motion?
This result feels like creepy perpetual motion. It’s like they’re teaching the AI ethics by making it write an ethics textbook and then read the textbook it just wrote. Is this a free lunch? Shouldn’t it be impossible for the AI to teach itself any more ethics than it started out with?
This gets to the heart of a question people have been asking AI alignment proponents for years: if the AI is so smart, doesn’t it already know human values? Doesn’t the superintelligent paperclip maximizer know that you didn’t mean for it to turn the whole world into paperclips? Even if you can’t completely specify what you want, can’t you tell the AI “you know, that thing we want. You have IQ one billion, figure it out”?
The answer has always been: a mind is motivated by whatever it’s motivated by. Knowing that your designer wanted you to be motivated by something else doesn’t inherently change your motivation.
I know that evolution optimized my genes for having lots of offspring and not for playing video games, but I would still rather play video games than go to the sperm bank and start donating. Evolution got one chance to optimize me, it messed it up, and now I act based on what my genes are rather than what I know (intellectually) the process that “designed” me “thought” they “should” be.
 The only guy doing it right by evolutionary standards (source)
The only guy doing it right by evolutionary standards (source)
In the same way, if you asked GPT-4 to write an essay on why racism is bad, or a church sermon against lying, it could do a pretty good job. This doesn’t prevent it from giving racist or false answers. Insofar as it can do an okay MLK Jr. imitation, it “knows on an intellectual level” why racism is bad. That knowledge just doesn’t interact with its behavior, unless its human designers take specific action to change that.
Constitutional AI isn’t free energy; it’s not ethics module plugged back into the ethics module. It’s the intellectual-knowledge-of-ethics module plugged into the motivation module. Since LLMs’ intellectual knowledge of ethics goes far beyond the degree to which their real behavior is motivated by ethical concerns, the connection can do useful work.
As a psychiatrist, I can’t help but compare this to cognitive behavioral therapy. A patient has thoughts like “everyone hates me” or “I can’t do anything right”. During CBT, they’re instructed to challenge these thoughts and replace them with other thoughts that seem more accurate to them. To an alien, this might feel like a perpetual motion machine - plugging the brain back into itself. To us humans, it makes total sense: we’re plugging our intellectual reasoning into our emotional/intuitive reasoning. Intellect isn’t always better than intuition at everything. But in social anxiety patients, it’s better at assessing whether they’re really the worst person in the world or not. So plugging one brain module into another can do useful work.
But another analogy is self-reflection. I sometimes generate a plan, or take an action - and then think to myself “Is this really going to work? Is it really my best self? Is this consistent with the principles I believe in?” Sometimes I say no, and decide not to do the thing, or to apologize for having done it. Giving AI an analogue of this ability takes it in a more human direction.
Does This Solve Alignment?
If you could really plug an AI’s intellectual knowledge into its motivational system, and get it to be motivated by doing things humans want and approve of, to the full extent of its knowledge of what those things are3 - then I think that would solve alignment. A superintelligence would understand ethics very well, so it would have very ethical behavior. How far does Constitutional AI get us towards this goal?
As currently designed, not very far. An already trained AI would go through some number of rounds of Constitutional AI feedback, get answers that worked within some distribution, and then be deployed. This suffers from the same out-of-distribution problems as any other alignment method.
What if someone scaled this method up? Even during deployment, whenever it planned an action, it prompted itself with “Is this action ethical? What would make it more ethical?”, then took its second-draft (or n-th draft) action instead of its first-draft one? Can actions be compared to prompts and put in an input-output system this way? Maybe; humans seem to be able to do this, although our understanding of our behavior may not fully connect to the deepest-level determinants of our behavior, and sometimes we fail at this process (ie do things we know are unethical or against our own best interests - is this evidence we’re not doing self-reflection right?)
But the most basic problem is that any truly unaligned AI wouldn’t cooperate. If it already had a goal function it was protecting, it would protect its goal function instead of answering the questions honestly. When we told it to ask itself “can you make this more ethical, according to human understandings of ‘ethical’?”, it would either refuse to cooperate with the process, or answer “this is already ethical”, or change its answer in a way that protected its own goal function.
What if you had overseer AIs performing Constitutional AI Feedback on trainee AIs, or otherwise tried to separate out the labor? There’s a whole class of potential alignment solutions where you get some AIs to watch over other AIs and hope that the overseer AIs stay aligned and that none of the AIs figure out how to coordinate. This idea is a member in good standing of that class, but it’s hard to predict how they’ll go until we better understand the kind of future AIs we’ll be dealing with.
Constitutional AI is a step forward in controlling the inert, sort-of-goal-less language models we have now. In very optimistic scenarios where superintelligent AIs are also inert and sort-of-goal-less, Constitutional AI might be a big help. In more pessimistic scenarios, it would at best be one tiny part of a plan whose broader strokes we still can’t make out.
-
Commenters point out that there’s another round of training involving fine-tuning; that’s not relevant here so I’m going to leave it out for simplicity.
-
Also less helpful at a given level of harmlessness, which is bad. I think these kinds of verbal framings are less helpful than looking at the graph, which suggests that quantitatively the first (good) effect predominates. I don’t know whether prioritizing harmlessness over helpfulness is an inherent feature of this method, a design choice by this team, or just a coincidence based on what kind of models and training sessions they used.
-
This sentence is deliberately clunky; it originally read “ethical things to the full extent of its knowledge of what is ethical”. But humans might not support maximally ethical things, or these might not coherently exist, so you might have to get philosophically creative here.