Davidson On Takeoff Speeds
The face of Mt. Everest is gradual and continuous; for each point on the mountain, the points 1 mm away aren’t too much higher or lower. But you still wouldn’t want to ski down it.
I thought about this when reading What A Compute-Centric Framework Says About Takeoff Speeds , by Tom Davidson. Davidson tries to model what some people (including me) have previously called “slow AI takeoff”. He thinks this is a misnomer. Like skiing down the side of Mount Everest, progress in AI capabilities can be simultaneously gradual, continuous, fast, and terrifying. Specifically, he predicts it will take about three years to go from AIs that can do 20% of all human jobs (weighted by economic value) to AIs that can do 100%, with significantly superhuman AIs within a year after that.
As penance for my previous mistake, I’ll try to describe Davidson’s forecast in more depth.
Raising The Biological Anchors
Last year I wrote about Open Philanthropy’s Biological Anchors, a math-heavy model of when AI might arrive. It calculated how fast the amount of compute available for AI training runs was increasing, how much compute a human-level AI might take, and estimated when we might get human level AI (originally ~2050; an update says ~2040)
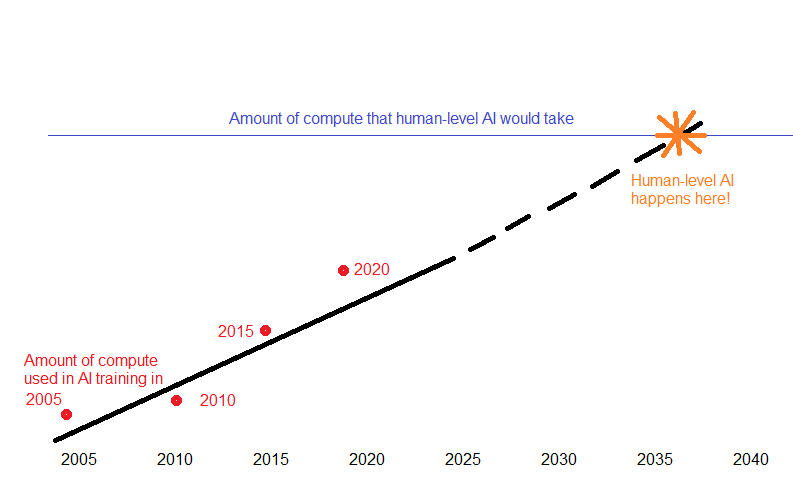 The basic Bio Anchors model
The basic Bio Anchors model
Compute-Centric Framework (from here on CCF) update Bio Anchors to include feedback loops: what happens when AIs start helping with AI research?
In some sense, AIs already help with this. Probably some people at OpenAI use Codex or other programmer-assisting-AIs to help write their software. That means they finish their software a little faster, which makes the OpenAI product cycle a little faster. Let’s say Codex “does 1% of the work” in creating a new AI.
Maybe some more advanced AI could do 2%, 5%, or 50%. And by definition, an AGI - one that can do anything humans do - could do 100%. AI works a lot faster than humans. And you can spin up millions of instances much cheaper than you can train millions of employees. What happens when this feedback loop starts kicking in?
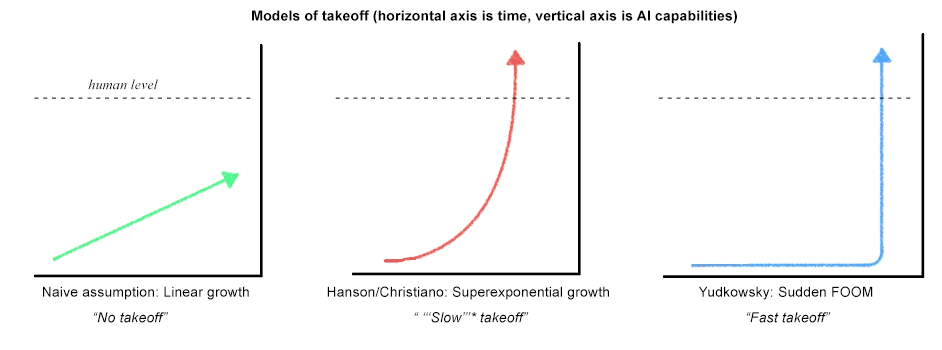
You get what futurists call a “takeoff”.
The first graph shows a world with no takeoff. Past AI progress doesn’t speed up future AI progress. The field moves forward at some constant rate.
The second graph shows a world with a gradual “slow” takeoff. Early AIs (eg Codex) speed up AI progress a little. Intermediate AIs (eg an AI that can help predict optimal parameter values) might speed up AI research more. Later AIs (eg autonomous near-human level AIs) could do the vast majority of AI research work, speeding it up many times. We would expect the early stages of this process to take slightly less time than we would naively expect, and the latter stages to take much less time, since AIs are doing most of the work.
The third graph shows a world with a sudden “fast” takeoff. Maybe there’s some single key insight that takes AIs from “mere brute-force pattern matchers” to “true intelligence”. Whenever you get this insight, AIs go from far-below-human-level to human-level or beyond, no gradual progress necessary.
Before, I mentioned one reason Davidson doesn’t like these terms - “slow takeoff” can be fast. It’s actually worse than this; in some sense, a “slow takeoff” will necessarily be faster than a “fast takeoff” - if you superimpose the red and blue graphs above, the red line will be higher at every point1. CCF departs from this terminology in favor of trying to predict a particular length of takeoff in real time units. Specifically, it asks: how long will it take to go from the kind of early-to-intermediate AI that can automate 20% of jobs, to the truly-human-level AI that can automate 100% of jobs?
(“Can automate” here means “is theoretically smart enough to automate” - actual automation will depend on companies fine-tuning it for specific tasks and providing it with the necessary machinery; for example, even a very smart AI can’t do plumbing until someone connects it to a robot body to do the dirty work. CCF will talk more about these kinds of considerations later.)
In order to figure this out, it needs to figure out the interplay of a lot of different factors. I’m going to focus on the three I find most interesting:
-
How much more compute does it take to train the AI that can automate 100% of the economy, compared to the one that can automate 20%?
-
How will existing AI produce feedback loops that speed (or slow) AI progress?
-
What are the bottlenecks to AI’s ability to speed AI progress, and how much do they matter?
How Much More Compute Does It Take To Train The AI That Can Automate 100% Of The Economy, Compared To The One That Can Automate 20%?
Like Bio Anchors, CCF ranks all current and future AIs on a one-dimensional scale: how much effective compute does takes to train them? It assumes that more effective compute = more intelligence. See the discussion of Bio Anchors for a justification of this assumption.
(everyone agrees that software/algorithmic progress can make AIs work better even with the same amount of compute; “effective compute” means “compute adjusting for software/algorithmic progress”)
Training a current AI like GPT-4 takes about 10^24 FLOPs of compute2. Bio Anchors has already investigated how much compute it would take to train a human-level AI; their median estimate is 10^35 FLOPs3.
Current AI (10^24 FLOPs) can’t do very many jobs4. Human level AI (10^35 FLOPs) by definition can do 100% of jobs. The AI that can do 20% of jobs must be somewhere in between. So the compute difference must be less than 12 orders of magnitude (OOMs)5.
Current AI seems far from doing 20% of jobs6, so Davidson artificially subtracts 3 OOMs to represent the lowest number at which it seems maybe possible that we would reach this level. Now we’re at a 9 OOM gap.
It seems like maybe dumb people can do 20% of jobs, so an AI that was as smart as a dumb human could reach the 20% bar. The compute difference between dumb and smart humans, based on brain size and neuron number, is less than 1 OOM, so this suggests a very small gap. But AI can already do some things dumb humans can’t (like write coherent essays with good spelling and punctuation), so maybe this is a bad way of looking at things.
GPT-4 is better than GPT-3, but maybe not the same amount of better that an AI that did 100% of human jobs would have to be over an AI that did 20% of human jobs. That suggests the gap is bigger than the 2 OOMs that separate GPT-4 from GPT-3.
Using a lot of hand-wavy considerations like these, Davidson estimates the effective FLOP gap with a probability distribution between 1 and 9 OOMs, densest around 4 OOMs.
How Will AI Produce Feedback Loops That Speed (Or Slow) AI Progress?
Davidson’s model looks like this:
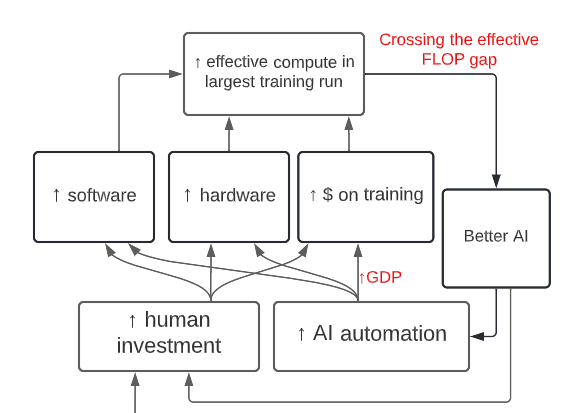
First, AI will look exciting in rigged demos. This will convince investors to pour more money into AI, meaning AI companies can afford bigger training runs (at the same $/FLOP cost), meaning AI progress goes faster.
Second, AI can speed up AI research directly, both in the boring sense where this is happening today (eg Codex) and the exciting sense where one day they can design entire new computer systems without our help.
AI Will Look Exciting And Spark Investor Interest
Way back in January 2023 when Davidson released his report, this hadn’t happened yet. He was just speculating that it might.
He models this with a discontinuity called “wakeup time”. Before wakeup time, compute grows at its current rate, with only a few risk-seeking investors willing to spend money on compute for AI training runs.
After wakeup time, everyone realizes AI is a big deal, and the amount of money available for AI training runs goes way up.
Davidson guesses wakeup time will happen around 2034, which now feels way too conservative. Are we already past wakeup time? I’m not sure - one of Davidson’s analogies is a wartime footing, and I don’t feel like we’ve gotten quite that obsessed with AI funding yet. Realistically a single “wakeup time” was a modeling decision made for the sake of convenience, and wakeup is a gradual process which has started but will get more intense as time goes on.
The model has AI investment grow at approximately its current rate until wakeup time, then grow at some higher rate similar to investment in munitions during wartime, or the highest rate at which the semiconductor industry has grown during periods of intense investment in the past.
AI Will Automate Research Directly
I was surprised to learn that economics already has well-known models for dealing with this kind of question. The key is that AI substituting for human labor is just a special case of capital substituting for human labor, something people have been modeling forever. The relevant tool is called a constant elasticity of substitution model.
I can’t follow the full math, but I appreciated this sample problem (source, further discussion):
[How long will it take AGI to double the quality of AI software? The answer] depends on i) how many human researcher-years are needed to double software when we first get AGI, and ii) how many AGIs you can run (where each AGI is as productive as a human per day).
Here’s a very rough estimate of (i). If there are 20,000 high-quality human researchers on software today and software doubles every ~2 years then it currently takes 40,000 researcher years to double 2020-FLOP per FLOP. Let’s assume this is ~100X higher by the time we get AGI due to diminishing returns from the research that happens before then. That implies ~4 million researcher-years to double software when we get AGI.
To estimate (ii), suppose you trained AGI with 1e32 2020-FLOP, the training run took 4 months, afterwards you used 10% of your training compute to run AGIs doing software research, and running an AGI required 1e16 2020-FLOP/s. With these conservative assumptions, you’ll have 100 million AGIs doing software research and so the first software doubling will take ~1 months.
That is: it takes much more compute to train an AI than to run it. Once you have enough compute to train an AI smart enough to do a lot of software research, you have enough compute to run 100 million copies of that AI7. 100 million copies is enough to do a lot of software research. If software research is parallelizable (ie if nine women can produce one baby per month - the analysis will investigate this assumption later), that means you can do it really fast.
What Are The Bottlenecks To AI Speeding Up AI Progress?
This is another case where armchair futurists have been arguing in circles for decades, and Davidson just turns the whole problem into a parameter that he can plug into a standard economic model. It’s pretty refreshing.
The argument: suppose you have a superintelligent AI. It can do amazing things like design a working starship with mere seconds of thought. Sounds like we’ll have working starships pretty soon, right?
No, say the skeptics. Imagine that this starship is as far beyond us as we are beyond the ancient Romans. And imagine going back to ancient Rome with the schematics for a stealth bomber. Even if you understand all the tech perfectly, and all the Romans were on board with helping you, it would take centuries to laboriously build up the coal industry, then the oil industry, then the steel industry, then the aluminum industry, then the plastics industry, then the microchip industry, and so on, before you could even begin to assemble the bomber itself.
 DALL-E: “The ancient Romans build a B-2 stealth bomber.” I’m not sure how stealthy this would be, but it’s not like the Visigoths have great radar.
DALL-E: “The ancient Romans build a B-2 stealth bomber.” I’m not sure how stealthy this would be, but it’s not like the Visigoths have great radar.
Wait, say the believers. The superintelligent AI doesn’t need to wait for humans to advance to the tech level where they can build its starship. If it’s so smart, it can design starship-factory-building robots! If the starship needs antimatter, it can design antimatter-factory-building robots! And so on.
No, say the skeptics - who’s going to build these starship-factory-building robots? Humans, that’s who. And humans don’t currently have a robotics industry that can plausibly build something so advanced. Starship-factory-building-robots are step N-2 on the N-step path to building a starship, and each of these steps are going to take a long time.
Wait, say the believers! If the AI’s so smart, it can come up with clever ways to retool existing technology to make starship-factory-building robots really quickly! Or it can genetically engineer micro-organisms to build starship-factory-building robots! Or it can create nanomachines! Or . . .
Eventually this all bottoms out in claims about what kind of technological progress something much smarter than us can think up. Obviously we are not smart enough to assess this clearly, so the debate endures.
In Davidson’s model, we’re mostly talking about AI design technologies. A lot of AI design is software work, which seems promising - if you’re smart enough to code really good software, you can just do that, no factories needed. But current AI design also involves compute-heavy training runs and hard-to-manufacture microchips. There’s no substitute for waiting months for your compute-heavy training run to finish, and chips require complicated chip fabs that you can’t just think into existence.
In the believers’ world, with few bottlenecks, these 100 million new software-design AIs that you just created can do 100 million times the work of a human workers, and software design will happen blindingly fast. In the extreme case, intellectual work is so cheap, and everything else so expensive, that AI routes around everything that requires training or new chips; see the discussion of “software-only singularity” in the appendices here.
In the skeptics’ world, software development is bottlenecked by compute and chip manufacturing. The first few thousand of these AIs will do all the work you can do without waiting for a long training run and a new chip fab. Then they’ll just sit there uselessly until the long training run happens and the new chip fab gets built. Software development might go a little faster, but not by much.
(of course, you’ll have other very smart AIs working on obtaining more compute and building chip fabs quicker - the question is whether there are some tasks that inherently bottleneck the process no matter how much cognitive labor you’re throwing at the whole chain)
Davidson’s economic solution to this problem is a parameter called ρ in the CES models, which represent how bottlenecked a process is - to what degree capital can 100% substitute for labor across all tasks, versus whether everything will be held up by a few tasks that are inherently labor-heavy. In the AI context, it represents the degree to which progress gets slowed done by tasks that AI can’t perform (because slow humans have to do it, or because the task requires some physical machinery). Models can set ρ at 0 (representing no bottlenecks), positive numbers (meaning labor and capital are substitutes) or negative numbers (meaning labor gets bottlenecked by a lack of capital, or vice versa).
Davidson says that in the economic contexts most similar to this, ρ = -0.5, and plugs that into his model.
So How Fast Is Takeoff?
I’ve just gone over the highlights. Davidson’s full model has sixteen main parameters and fifty “additional parameters”. Each is represented as a distribution of possible values.
He goes on to do a Monte Carlo simulation, where he selects one possible value from the distribution of each variable, and simulates the resulting world. Then he averages out all those simulations to get a “mainline world”.
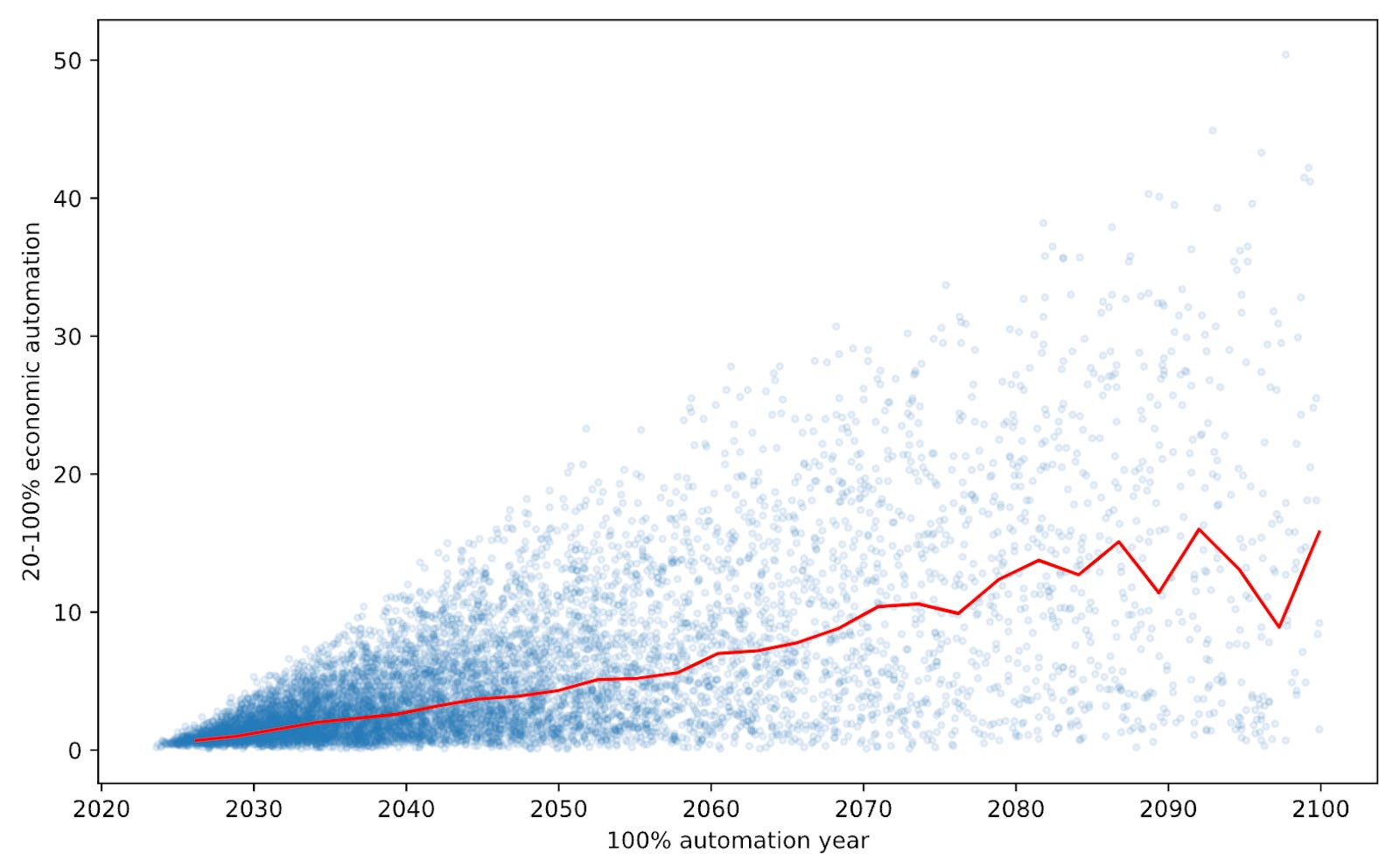 An example of one of CCF’s Monte Carlo analyses.
An example of one of CCF’s Monte Carlo analyses.
Here’s his median scenario, represented in two ways:
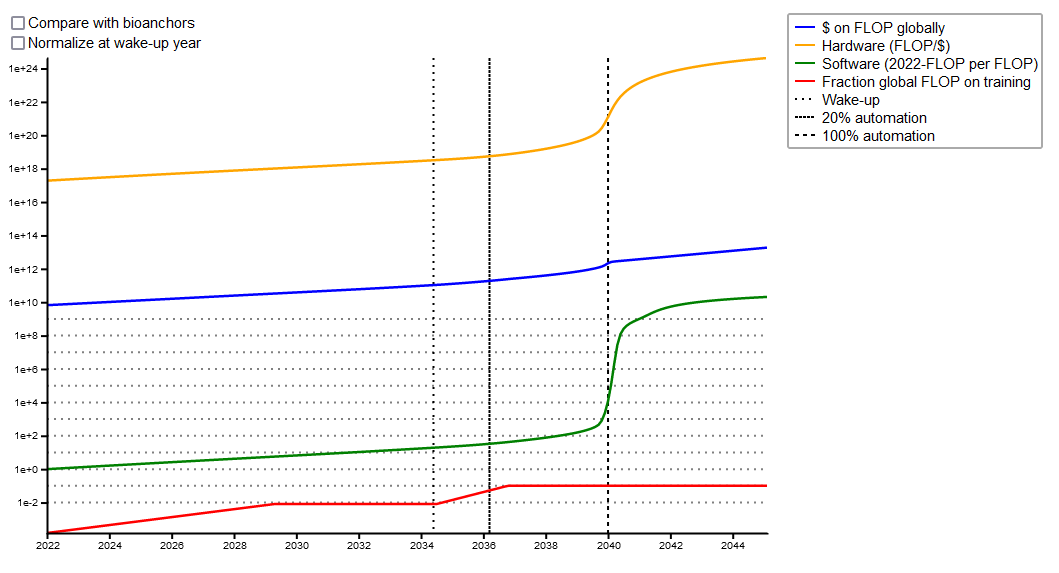

The first graph shows the various inputs to compute; the second graph just shows how much compute the biggest AI in each year probably has.
In 2022, AIs had around 10^24 FLOPs. Davidson expects this to grow by about an OOM per year for a while, mostly because companies and investors are getting more excited about AI and paying for bigger training runs, although a little of this is also software and hardware progress. The line might go a little bit up or down based on the size of investor pocketbooks and when “wakeup time” happens.
Around 2040, AI will reach the point where it can do a lot of the AI and chip research process itself. Research will speed up VERY VERY FAST. AI will make more progress in two years than in decades of business-as-usual. Most of this progress will be in software, although hardware will also get a big boost.8
So this is the mainline scenario. What are the confidence intervals?
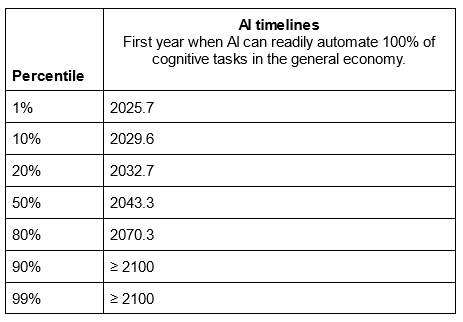
The commentary around Bio Anchors made me suspect that every AI timelines prediction is based on vibes. Forecasters rig their model to match whatever the current vibes are. This doesn’t have to be a conscious, sinister process. It just means that you have a lot of parameters, and if your model gives an insane result, you reconsider your parameter value estimates. And then you keep doing that until your model gives the sanest result of all, ie the one that exactly matches the current vibes.
The current vibes are human-level AI in the 2030s or early 2040s. CCF says 2043, so it matches the vibes very well. This doesn’t mean Davidson necessarily rigged it. Maybe it’s just a really great model.
But I do have one concern: CCF has to predict human-level AI sooner than Bio Anchors, since it adds a consideration (intelligence explosion) which accelerates AI. The original Bio Anchors said 2052, so CCF’s 2043 is a reasonable correction.
But a few months ago, Ajeya Cotra of Bio Anchors updated her estimate to 2040. Some of this update was because she read CCF and was convinced, but some was because of other considerations. Now CCF is later than (updated) Bio Anchors. Someone is wrong and needs to update, which might mean we should think of CCF as predicting earlier than 2043. I suggest discovering some new consideration which allows a revision to the mid-2030s, which would also match the current vibes.
What about takeoff speeds?
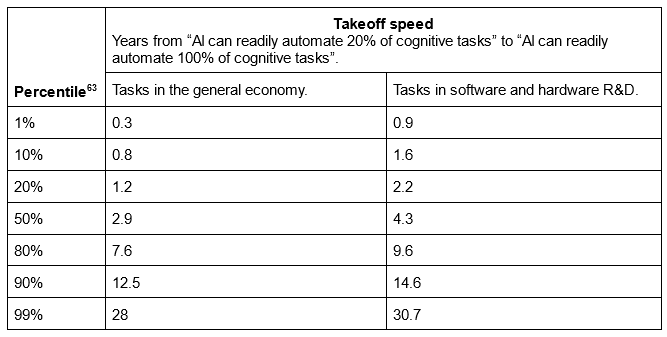
I’m less cynical about this one. There are no pre-existing vibes about takeoff speeds. Also, this sounds kind of crazy, which is a good sign that it isn’t rigged.
From when AI can do 20% of jobs, Davidson expects it will only take about 3 years for it to be able to do 100% of jobs. This would be less worrying if I was sure that AI couldn’t do 20% of jobs now.
Finally:
How much time from AGI to superintelligence? This has not been my main focus, but the framework has implications for this question. My best guess is that we go from AGI (AI that can perform ~100% of cognitive tasks as well as a human professional) to superintelligence (AI that very significantly surpasses humans at ~100% of cognitive tasks) in 1 - 12 months. The main reason is that AGI will allow us to >10X our software R&D efforts, and software (in the “algorithmic efficiency” sense defined above: effective FLOP per actual FLOP) is already doubling roughly once per year.
Yeah, this is an obvious implication of this model. He who has ears to hear, let him listen.
Everyone’s Favorite Part - The Sensitivity Analysis
No, really, this is important.
Partly because every number in this model is at best an educated guess and at worst a wild guess. If small changes in their value change the result a lot, it’s useless. If the result stays steady across a wide range of plausible changes, then it’s worth taking seriously.
But also, Nostalgebraist argues that Bio Anchors hinges almost entirely on Moore’s Law. It’s no sin to hinge entirely on one very important value. But Bio Anchors looks like a very sophisticated piece of math with lots of parameters, and if you judge it on that basis, instead of on “well, everything depends on Moore’s Law, but Moore’s Law is hard to predict”, then you might get a false impression. Does CCF hinge on one specific parameter?
You can read the parameter importance analysis summary here and the full the sensitivity analysis here, but I prefer the “playground” widget :
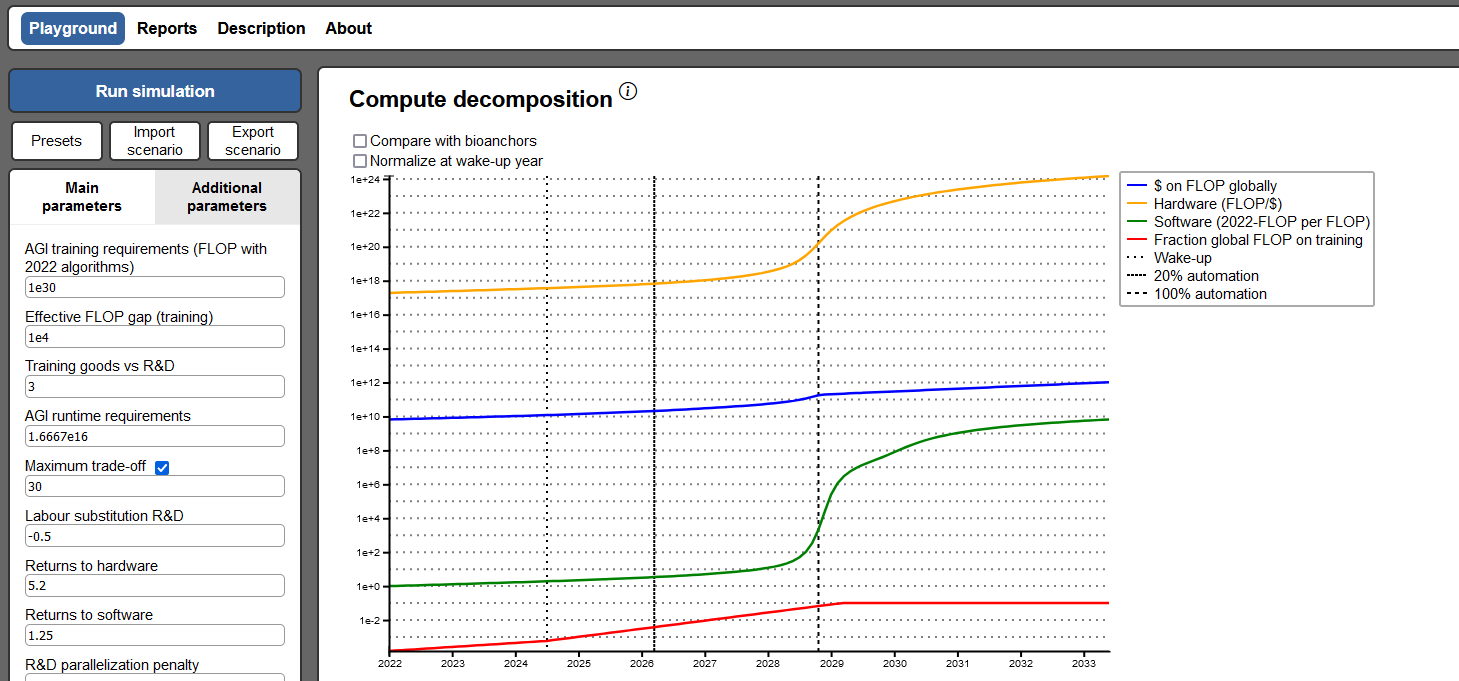
It demonstrates that the timeline estimates are pretty sensitive; for example, if you increase/decrease the estimate of how much compute it will take to build AGI, the date of AGI moves back/forward appropriately. But it’s harder to set the parameters to a value where there isn’t some kind of intelligence explosion, ie an “S” shape on the hardware and (especially) software progress curves.
One way to remove the explosion is to choose a very low value for “R&D parallelization penalty”. This term represents the fact that “nine women can’t make one baby per month”; at some point adding more simultaneous labor doesn’t speed up tasks as much as you’d think, because the tasks have to be done in a certain order, or communication problems eat up all the gains. Setting this close to zero means there’s not much benefit to your 100 million AI laborers and intelligence doesn’t really explode.
Another way to remove the explosion is to set “labor substitution R&D” close to zero. I think this is ρ , the bottleneck constant discussed above. A number close to zero means that bottlenecks completely dominate, and your 100 million AI laborers spend all their time waiting for some normal human to run the chip manufacturing conveyor belt.
My impression is that preventing the intelligence explosion requires setting these to values that don’t really match observations from real world economics. But having 100 million disembodied cognitive laborers is a pretty unusual situation and maybe it will turn out to be unprecedentedly bottlenecked or non-parallelizable.
There must be a few other things that can remove the intelligence explosion, because switching from the “best guess” to “conservative” preset on the Playground removes it even when I manually set those two parameters back to their normal values. But it’s not any of the big obvious things, and most changes push timelines backward or forward a bit without altering the shape of the curve.
Contra MIRI On Takeoff Speeds
A lot of these big complicated analyses are salvos in a long-running conflict between a school of futurists based at Open Philanthropy and another school based at the Machine Intelligence Research Institute.
The OP school expect the rise of AI to be gradual, multipolar, and potentially survivable. The MIRI school expect it to be sudden, singular, and catastrophic. Yudkowsky vs. Christiano on Takeoff Speeds is a good intro here, with Yudkowsky representing MIRI and Christiano OP.
Davidson works at Open Philanthropy and is trying to flesh out their side of the story. Again, even his “gradual” takeoff won’t seem very gradual to us fleshbag humans; it will go from 20% of the economy to 100% in ~3 years, and reach superintelligence within a year after that9. Still, there will at least be enough time for journalists to publish a few articles saying that fears of AI taking over 100% of the economy are overblown and alarmist, which is a sort of gradual.
The last part of CCF is a response to MIRI, shading into an acknowledgment that the report has mostly assumed away their concerns.
Davidson defines his difference from MIRI in terms of the shape of the compute/capabilities graph. He thinks it looks more like this:
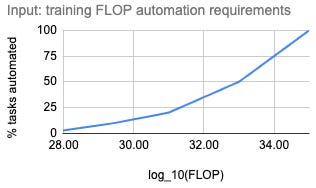
And MIRI’s position, represented on a similar graph, might look more like this:
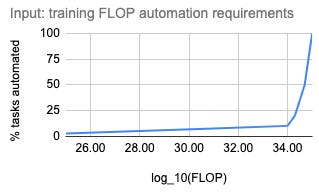
That’s just an example; MIRI’s isn’t claiming that there will be a discontinuity at 10^34 FLOPs in particular, or even that the discontinuity will be caused by reaching any particular amount of training compute. Just that someone might develop a new paradigm of AI that works much better than deep learning, and all of these arguments about compute will become irrelevant.
Why does MIRI expect something like this? I think lots of reasons, some of them pretty arcane, but the most popular one for debate has been the chimp/human transition. It intuitively feels like lemurs, gibbons, chimps, and homo erectus were all more or less just monkey-like things plus or minus the ability to wave sharp sticks - and then came homo sapiens , with the potential to build nukes and travel to the moon. In other words, there wasn’t a smooth evolutionary landscape, there was a discontinuity where a host of new capabilities became suddenly possible. Once AI crosses that border, we should expect to be surprised by how much more powerful it becomes.
Since then, many people have criticized this argument. Paul Christiano objections that evolution wasn’t directly optimizing chimps for engineering skills, so there was an engineering-skills overhang that got unbottlenecked all at once; for other objections, see Evolution Provides No Argument For The Sharp Left Turn. Davidson tries to steelman MIRI’s scenario: imagine evolution was optimizing for speed. It created cheetahs, falcons, etc. Then by some freak coincidence, it creates humans (even though they are not very fast). Humans proceed to invent cars and rockets. Now it’s obvious that humans are a paradigm shift, and the overhang argument is neutralized.
Davidson’s response is just sort of “yeah, maybe, I guess”:
This argument does update me towards C=“maybe some new AI technique will be developed over the course of a few months and cause AI capabilities to improve OOMs faster”.
But the update is relatively small (this feels like evidence i’m ~2-3X as likely to see in worlds where C is true):
We haven’t actually observed ‘hypothetical evolution’ so don’t know what would happen.
Even if we had, it’s just one example so provides limited evidence.
Evolution is different from “the process of AI R&D” in some important ways. (They would be much more analogous if AI R&D simply consisted of one massive gradient descent training run. I flesh this out in the final objection, which I find pretty convincing.)
This line of argument can be interpreted as “evidence for an extremely narrow FLOP gap”, but the evidence seems more speculative and indirect than the numerous other sources of evidence I considered. So it doesn’t seem like this should substantially shift my probability distribution over the FLOP gap.
I’m not sure why exactly you would think of this as a FLOP gap. A sufficiently new paradigm might allow better results with fewer FLOPs, not just a smaller increase in FLOPs than you would otherwise expect. And it could come at any point along the FLOP progress graph - you wouldn’t need to reach 10^34 FLOPs to get it; a sufficiently smart person might be able to come up with it today.
Still, I don’t think any of this really matters. Davidson is admitting he’s not really modeling this, and if this is how you think of things you will not like his model. This is a model about how the current paradigm will proceed; you can take it or leave it.
Conclusion
Like skiing down Everest, near-future AI capabilities progress may be simultaneously gradual, continuous, and fast. Also exhilarating, terrifying, and potentially fatal to the unprepared.
Since everything will happen faster than we think, we will want to have plans beforehand. We need clear criteria for when AI labs will halt progress to reassess safety - not just because current progress is fast, but because progress will get faster just when it becomes most dangerous.
Sometime in the next few years or decades, someone will create an AI which can perform an appreciable fraction of all human tasks. Millions of copies will be available almost immediately10, with many running at faster-than-human speed. Suddenly, everyone will have access to a super-smart personal assistant who can complete cognitive tasks in seconds. A substantial fraction of the workforce will be fired; the remainder will see their productivity skyrocket. The pace of technological progress will advance by orders of magnitude, including progress on even smarter AI assistants. Within months, years at most, your assistant will be smarter than you are and hundreds of millions of AIs will be handling every facet of an increasingly futuristic-looking economy.
When this happens, Tom Davidson and OpenPhil will be able to say “We drew a curve whose shape sort of corresponds to this process.” It probably won’t feel very reassuring.
It’s a mixture of approaching fundamental limits to hardware and software, [and] failing to model the process by which AIs can design better and better robots, and then those robots double the number of robots and the number of AI chips faster and faster, driving accelerating (hyperbolic!) growth in the number of robots and AI chips. This is because I was mostly trying to model the development of AGI and the immediate aftermath, and because the model was already much too complicated to be thinking about robots!
-
Is this just an artifact of where I put the fast takeoff cliff on the graph? The broader point is that if there is some quantum leap waiting somewhere along the AI progress slope, we will get to it faster if we model AIs self-improving gradually until then, instead of humans doing AI research alone. Put another way, the people in this picture of fast takeoff get to the cliff faster than they would if they weren’t even-a-little in the slow takeoff world.
-
Although some estimates for GPT-4 are closer to 10^25 FLOPs. Davidson’s report was published in January, when the biggest AIs were closer to 10^24 FLOPs, and since we don’t have good numbers for GPT-4 I am sticking with his older number for consistency and convenience.
-
But with ~10 OOM error bars!
-
Is this true? It was probably more true in January 2023, when Davidson wrote his report. He tries to think of this in economic terms: AI companies are worth much less than 1% of the total economy. This doesn’t seem quite right to me; surely AI companies might capture only a fraction of the value they produce, especially given their habit of offering their products for free! Davidson acknowledges this, but says they’re so far below 1% of the economy that he is still comfortable saying they can (as of January 2023) automate less than 1% of jobs.
-
The report says 7.5 OOMs, which I think is just an error; otherwise I don’t understand how they got this number.
-
Again, back in the hoary days of January 2023.
-
It may also be possible to run these copies at faster-than-human speed. More analysis of this key issue here.
-
I asked Davidson why the curves level off at the end. He says:
-
Unless we choose to slow down, eg with government regulation or corporate self-regulation.
-
Unless the AI lab involved delays releasing it, either out of safety concerns or in order to keep it to themselves and gain a big advantage.