I Won My Three Year AI Progress Bet In Three Months
I.
DALL-E2 is bad at “compositionality”, ie combining different pieces accurately. For example, here’s its response to “a red sphere on a blue cube, with a yellow pyramid on the right, all on top of a green table”.

Most of the elements - cubes, spheres, redness, yellowness, etc - are there. It even does better than chance at getting the sphere on top of the cube. But it’s not able to track how all of the words relate to each other and where everything should be.
I ran into this problem in my stained glass window post. When I asked it for a stained glass window of a woman in a library with a raven on her shoulder with a key in its mouth, it gave me everything from “a library with a stained glass window in it” to “a half-human, half-raven abomination”.

At the time, I wrote:
I’m not going to make the mistake of saying these problems are inherent to AI art. My guess is a slightly better language model would solve most of them…for all I know, some of the larger image models have already fixed these issues. These are the sorts of problems I expect to go away with a few months of future research.
This proved controversial. Gary Marcus in particular has emphasized how challenging compositionality is for modern language and image models:
 Gary Marcus @GaryMarcusCompositionality is the wall. Even “red cube” and “blue cube” on their own are represented unreliably; not one of ten images correctly captures the full phrasal description. The images are beautiful, but no match for the precision of language.
Gary Marcus @GaryMarcusCompositionality is the wall. Even “red cube” and “blue cube” on their own are represented unreliably; not one of ten images correctly captures the full phrasal description. The images are beautiful, but no match for the precision of language.  David Madras @david_madrasThe ways in which #dalle is so incredible (and it is) really put a fine point on the ways in which compositionality is so hard https://t.co/I6DC4g53MK
David Madras @david_madrasThe ways in which #dalle is so incredible (and it is) really put a fine point on the ways in which compositionality is so hard https://t.co/I6DC4g53MK144Likes28Retweets](https://twitter.com/garymarcus/status/1512647983317151747?lang=en)
 Gary Marcus @GaryMarcusCompositionality is the wall. Even “red cube” and “blue cube” on their own are represented unreliably; not one of ten images correctly captures the full phrasal description. The images are beautiful, but no match for the precision of language. https://t.co/uvoXUtETwi
Gary Marcus @GaryMarcusCompositionality is the wall. Even “red cube” and “blue cube” on their own are represented unreliably; not one of ten images correctly captures the full phrasal description. The images are beautiful, but no match for the precision of language. https://t.co/uvoXUtETwi54Likes7Retweets](https://twitter.com/GaryMarcus/status/1512650166326628355)
And one of my commenters, Vitor, asked:
Why are you so confident in this? The inability of systems like DALL-E to understand semantics in ways requiring an actual internal world model strikes me as the very heart of the issue. We can also see this exact failure mode in the language models themselves. They only produce good results when the human asks for something vague with lots of room for interpretation, like poetry or fanciful stories without much internal logic or continuity.
Not to toot my own horn, but two years ago you were naively saying we’d have GPT-like models scaled up several orders of magnitude (100T parameters) right about now (https://slatestarcodex.com/2020/06/10/the-obligatory-gpt-3-post/#comment-912798).
I’m registering my prediction that you’re being equally naive now. Truly solving this issue seems AI-complete to me. I’m willing to bet on this (ideas on operationalization welcome).
I responded to Marcus here, and I responded to Vitor by making a bet on whether AI image models could draw some compositionality-heavy pictures by 2025. The specific terms we agreed on:
My proposed operationalization of this is that on June 1, 2025, if either if us can get access to the best image generating model at that time (I get to decide which), or convince someone else who has access to help us, we’ll give it the following prompts:
1. A stained glass picture of a woman in a library with a raven on her shoulder with a key in its mouth
2. An oil painting of a man in a factory looking at a cat wearing a top hat
3. A digital art picture of a child riding a llama with a bell on its tail through a desert
4. A 3D render of an astronaut in space holding a fox wearing lipstick
5. Pixel art of a farmer in a cathedral holding a red basketball
We generate 10 images for each prompt, just like DALL-E2 does. If at least one of the ten images has the scene correct in every particular on 3/5 prompts, I win, otherwise you do.
DALL-E can’t do any of these:
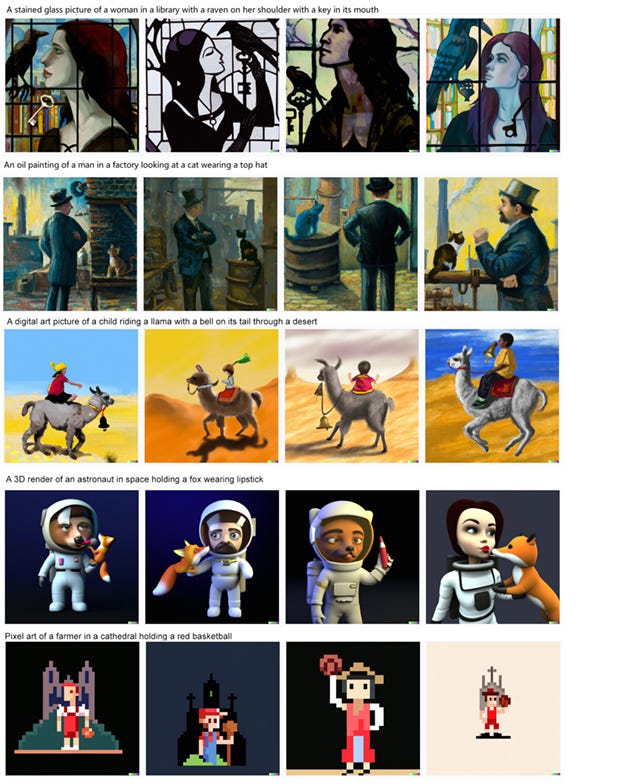
If I were being kind, I would give it the farmer in the cathedral. But I am being unkind, so the farmer in front of the cathedral doesn’t count.
II.
There are now at least four more AI image models available:
-
Google Imagen announced May 2022.
-
Google PARTI announced June 2022.
-
MidJourney announced July 2022.
-
Stability.ai StableDiffusion announced August 2022.
Thanks to some help from researchers, employees, and beta testers, I was able to run my prompts through some newer models (thanks especially to Google for eventually giving permission to do this despite their usually high security around these things). The results were:
-
DALLE-2: 0/5
-
Imagen: 3/5
-
PARTI: 2/5 (a third one was right in the 11th image!)
-
MidJourney: Forgot to test this one!
-
StableDiffusion: 0/5
Imagen got 3/5 and so I would say it wins the bet. There was one snafu, which was that for trust-and-safety reasons, Imagen will not represent the human form (maybe it’s a good Muslim?) We got around this by replacing all humans in the prompts with robots. It still registered surprisingly many trust-and-safety violations for these innocuous prompts, but here’s what we got (slightly edited to always include the best picture of 10):
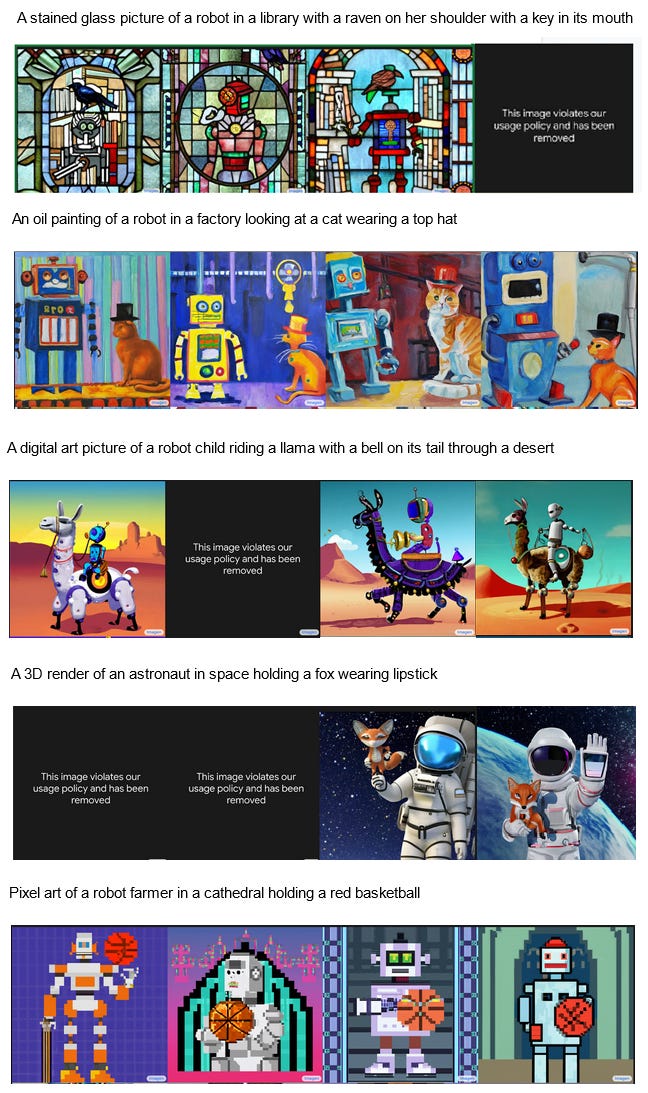
I think it got the cat, the llama, and the basketball, as long as you agree that the last image is sort of an attempt at a robot farmer (he’s wearing a little hat). I think the not-in-the-original-bet demand for it to be a robot complicated the farmer demand and so I’m prepared to give it a break here (that is, if we had only asked for it to be a farmer, it would have done as good a job making farmers as it did making robots).
It still fails the library scene, although it does better than DALL-E2 in realizing that the picture itself should be in the style of stained glass. It still fails the fox scene, although it does better than DALL-E2 in at least realizing that the fox should have the lipstick.
Without wanting to claim that Imagen has fully mastered compositionality, I think it represents a significant enough improvement to win the bet, and to provide some evidence that simple scaling and normal progress are enough for compositionality gains. Given these gains, it would surprise me (though by no means be impossible) if image model skill plateaued at this level rather than continuing to improve.
The original bet from June of this year was about whether AIs would be able to do this by 2025, ie three years from now. In fact, not only did they reach this level in three months, but probably they were at this level before the bet was even made - Google announced Imagen in May 2022; it just took me three months to convince someone there to run my prompts.
I think this matches the general finding that AI progress is faster than expected, and increases my certainty that scale and normal progress can sometimes be enough to solve even very difficult problems.