Mantic Monday 3/14/22
Ukraine Warcasting
Changes in Ukraine prediction markets since my last post February 28:
-
Will Kiev fall to Russian forces by April 2022?: 69% —→ 14%
-
Will at least three of six big cities fall by June 1?: 71% —→ 70%
-
Will World War III happen before 2050?: 20% —→21%
-
Will Putin still be president of Russia next February?: 71% —→ 80%
-
Will 50,000 civilians die in any single Ukrainian city?: 8% —→ 12%
-
Will Zelinskyy no longer be President of Ukraine on 4/22?: 63% —→20%
If you like getting your news in this format, subscribe to the Metaculus Alert bot for more (and thanks to ACX Grants winner Nikos Bosse for creating it!)
Numbers 1 and 7 are impressive changes! (it’s interesting how similarly they’ve evolved, even though they’re superficially about different things and the questions were on different prediction markets). Early in the war, prediction markets didn’t like Ukraine’s odds; now they’re much more sanguine.
Let’s look at the exact course:
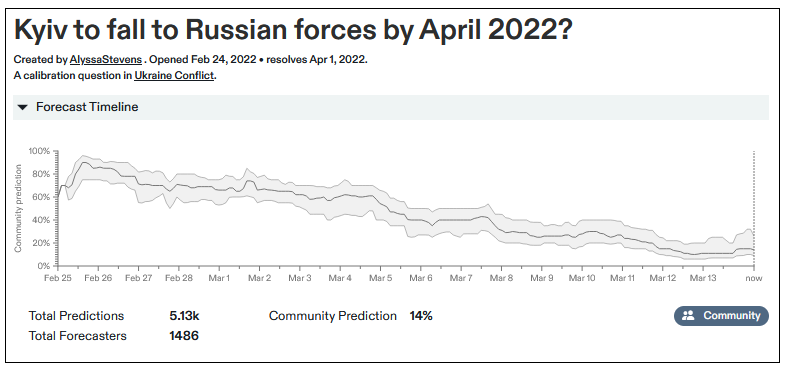
This is almost monotonically decreasing. Every day it’s lower than the day before.
How suspicious should we be of this? If there were a stock that decreased every day for twenty days, we’d be surprised that investors were constantly overestimating it. At some point on day 10, someone should think “looks like this keeps declining, maybe I should short it”, and that would halt its decline. In efficient markets, there should never be predictable patterns! So what’s going on here?
Maybe it’s a technical issue with Metaculus? Suppose that at the beginning of the war, people thought there was an 80% chance of occupation. Lots of people predicted 80%. Then events immediately showed the real probability was more like 10%. Each day a couple more people showed up and predicted 10%, which gradually moved the average of all predictions (old and new) down. You can see a description of their updating function here - it seems slightly savvier than the toy version I just described, but not savvy enough to avoid the problem entirely.
But Polymarket has the same problem:
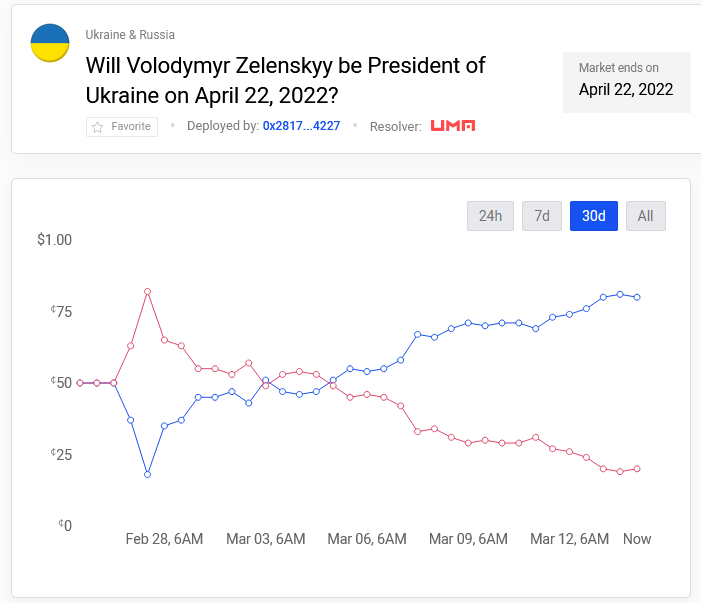
It shouldn’t be able to have technical issues like Metaculus, so what’s up?
One possibility is that, by a crazy coincidence, every day some new independent event happened that thwarted Russia and made Ukraine’s chances look better. Twenty dice rolls in a row came up natural 20s for Ukraine. Seems unlikely.
Another possibility is that forecasters started out thinking that Russia was strong, in fact Russia was weak, and every day we’ve gathered slightly more evidence for that underlying reality. I’m having trouble figuring out of if this makes sense. You’d still think that after ten straight days of that, people should say “probably tomorrow we’ll get even more evidence of the same underlying reality, might as well update today”.
A third possibility is that forecasters are biased against updating. A perfect Bayesian, seeing the failures of the Russian advance over the first few days, would have immediately updated to something like correct beliefs. But the forecasters here were too conservative and didn’t do that.
A fourth possibility is that forecasters biased towards updating too much. Ukrainian propaganda is so good that every extra day you’re exposed to it, you become more and more convinced that Ukraine is winning.
[EDIT: Commenter HouseAlwaysWins notes “If you plotted a prediction for “will this iodine-131 nucleus have decayed by April 1” you’d also get a roughly linear decline (unless it decayed in which case it would jump up to 100%). Prediction markets are allowed to have “story arcs”, so long as the expected change is zero.” Some other people make similar good points, which you can find in the comments section.]
Nuclear Warcasting
A friend recently invited me to their bolthole in the empty part of Northern California. Their argument was: as long as the US and Russia are staring menacingly at each other, there’s a (slight) risk of nuclear war. Maybe we should get out of cities now, and beat the traffic jam when the s#!t finally hits the fan.
I declined their generous offer, but I’ve been wondering whether I made the right call. What exactly is the risk of nuclear war these next few months?
Enter Samotsvety Forecasts. This is a team of some of the best superforecasters in the world. They won the CSET-Foretell forecasting competition by an absolutely obscene margin, “around twice as good as the next-best team in terms of the relative Brier score”. If the point of forecasting tournaments is to figure out who you can trust, the science has spoken, and the answer is “these guys”.
As a service to the community, they came up with a formal forecast for the risk of near-term nuclear war:
We aggregated the forecasts of 8 excellent forecasters for the question What is the risk of death in the next month due to a nuclear explosion in London? Our aggregate answer is 24 micromorts (7 to 61) when excluding the most extreme on either side. A micromort is defined as a 1 in a million chance of death. Chiefly, we have a low baseline risk, and we think that escalation to targeting civilian populations is even more unlikely.
For San Francisco and most other major cities, we would forecast 1.5-2x lower probability (12-16 micromorts). We focused on London as it seems to be at high risk and is a hub for the effective altruism community, one target audience for this forecast.
Given an estimated 50 years of life left, this corresponds to ~10 hours lost. The forecaster range without excluding extremes was <1 minute to ~2 days lost. Because of productivity losses, hassle, etc., we are currently not recommending that individuals evacuate major cities.
You can read more about their methodology and reasoning on the post on Effective Altruism Forum, but I found this table helpful:
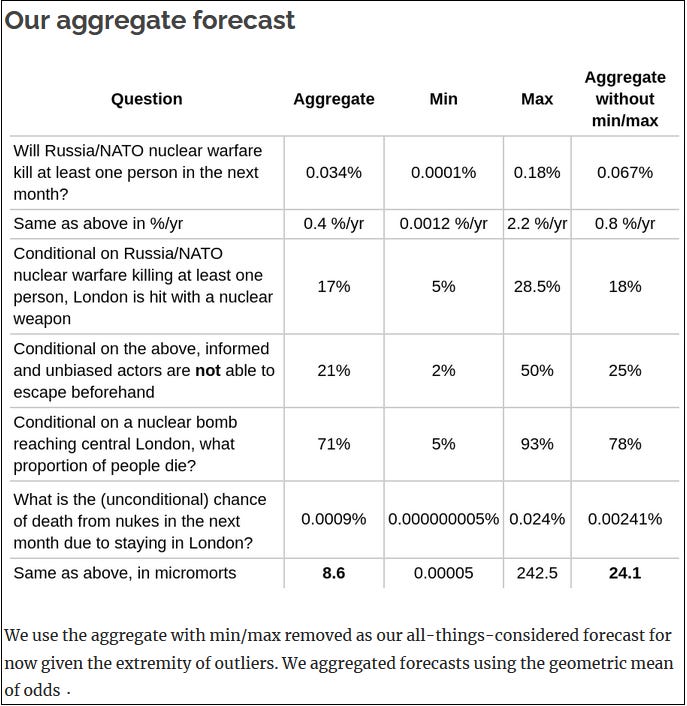
Along with reassuring me I made the right choice not to run and hide, this is a new landmark in translating forecasting results to the real world. The whole stack of technologies came together: tournaments to determine who the best predictors are, methods for aggregating probabilities, and a real-world question that lots of people care about. Thanks to Samotsvety and their friends for making this happen!
(see here for some pushback, disagreement, and back-and-forth)
Forecasters Vs. Experts
Also from the EA Forum this month: Comparing Top Forecasters And Domain Experts, by Arb Consulting (the team also includes one of the Samotsvety members who worked on the nuclear risk estimate).
Everyone always tells the story of how Tetlock’s superforecasters beat CIA experts. Is it true? Arb finds that it’s more complicated:
A common misconception is that superforecasters outperformed intelligence analysts by 30%. Instead: Goldstein et al showed that [EDIT: the Good Judgment Project’s best-performing aggregation method][2] outperformed the intelligence community, but this was partly due to the different aggregation technique used (the GJP weighting algorithm performs better than prediction markets, given the apparently low volumes of the ICPM market). The forecaster prediction market performed about as well as the intelligence analyst prediction market; and in general, prediction pools outperform prediction markets in the current market regime (e.g. low subsidies, low volume, perverse incentives, narrow demographics). [85% confidence]
In the same study, the forecaster average was notably worse than the intelligence community.
If I’m understanding this right, the average forecaster did worse than the average expert, but Tetlock had the bright idea to use clever aggregation methods for his superforecasters, and the CIA didn’t use clever aggregation methods for their experts. The CIA did try a prediction market, which in theory and under ideal conditions should work at least as well as any other aggregation method, but under real conditions (it was low-volume and poorly-designed) it did not.
They go on to review thirteen other studies in a variety of domains (keep in mind that different fields may have different definitions of “expert” and require different levels of expertise to master). Overall there was no clear picture. Eyeballing the results, it looks like forecasters often do a bit better than experts, but with lots of caveats and possible exculpatory factors. Sometimes the results seemed a little silly: in one, forecasters won because the experts didn’t bother to update their forecasts often enough as things changed; in another, “1st place went to one of the very few public-health professionals who was also a skilled Hypermind forecaster.”
They conclude:
To distinguish some claims:
1: “Forecasters > the public”
2: “Forecasters > simple models”
3: “Forecasters > experts”3a: “Forecasters > experts with classified info”
3b: “Averaged forecasters > experts”
3c: “Aggregated forecasters > experts”We think claim (1) is true with 99% confidence[1] and claim (2) is true with 95% confidence. But surprisingly few studies compare experts to generalists (i.e. study claim 3). Of those we found, the analysis quality and transparency leave much to be desired. The best study found that forecasters and health professionals performed similarly. In other studies, experts had goals besides accuracy, or there were too few of them to produce a good aggregate prediction.
So, kind of weak conclusion, but you can probably believe some vague thing like “forecasters seem around as good as experts in some cases”.
Also, keep in mind that in real life almost no one ever tries to aggregate experts in any meaningful way. Real-life comparisons tend to be more like “aggregated forecasters vs. this one expert I heard about one time on the news”. I’d go with the forecasters in a situation like this - but again, the studies are too weak to be sure!
Shorts
1:Taosumer reviews my Prediction Market Cube and asks why I don’t have “decentralized” on there as a desideratum. My answer: decentralization is great, but for me it cashes out in “ease of use” - specifically, it’s easy to use it because the government hasn’t shut it down or banned you. Or as “real money” - the reason Manifold isn’t real-money is because they’re centralized and therefore vulnerable and therefore need to obey laws. Or as “easy to create market” - the reason Kalshi doesn’t let you create markets is partly because it’s centralized and therefore vulnerable and therefore needs to limit markets to things regulators like. I agree that, because of those second order effects , decentralization is crucial and needs to be pursued more, and I agree that it’s a tragedy that [whatever happened to Augur] happened to Augur.
2: More people make Ukraine predictions: Maxim Lott, Richard Hanania (again), Samo Burja (again), EHarding (possibly trolling?), Robin Hanson (sort of)
3: Last month we talked about some problems with the Metaculus leaderboard. An alert reader told me about their alternative Points Per Question leaderboard, which is pretty good - although I think different kinds of questions give different average amounts of points so it’s still not perfect.
4: Also last month, I suggested Manifold Markets have a loan feature to help boost investment in long-term markets. They’ve since added this feature: your first $M20 will automatically be a zero-interest loan.
5: Related: I’m testing Manifold as a knowledge-generation device. If you want to help, go bet in the market about how I’ll rank interventions in an upcoming updated version of the Biodeterminists’ Guide To Pregnancy.
6:Reality Cards is a new site that combines the legal hassles of prediction markets with the technical hassles of NFTs. You bid to “rent” the NFT representing a certain outcome, your rent goes into a pot, and then when the event happens the pot goes to whoever held the relevant NFT. I’m not math-y enough to figure out whether this is a proper scoring rule or not, but it sure does sound unnecessarily complicated. I imagine everyone involved will be multimillionaires within a week.
7: In case a prediction market using NFTs isn’t enough for you, this article suggests that OpenDAO is working on a prediction market about NFTs. It claims they should be done by January, but I can’t find it.
