Mantic Monday 4/24/23
Can AIs Predict The Future? By Which We Mean The Past?
If we asked GPT-4 to play a prediction market, how would it do?
Actual GPT-4 probably would just give us some boring boilerplate about how the future is uncertain and it’s irresponsible to speculate. But what if AI researchers took some other model that had been trained not to do that, and asked it?
This would take years to test, as we waited for the events it predicted to happen. So instead, what if we took a model trained off text from some particular year (let’s say 2020) and asked it to predict forecasting questions about the period 2020 - 2023. Then we could check its results immediately!
This is the basic idea behind Zou et al (2022), Forecasting Future World Events With Neural Networks. They create a dataset, Autocast, with 6000 questions from forecasting tournaments Metaculus, Good Judgment Project, and CSET Foretell. Then they ask their AI (a variant of GPT-2) to predict them, given news articles up to some date before the event happened. Here’s their result:
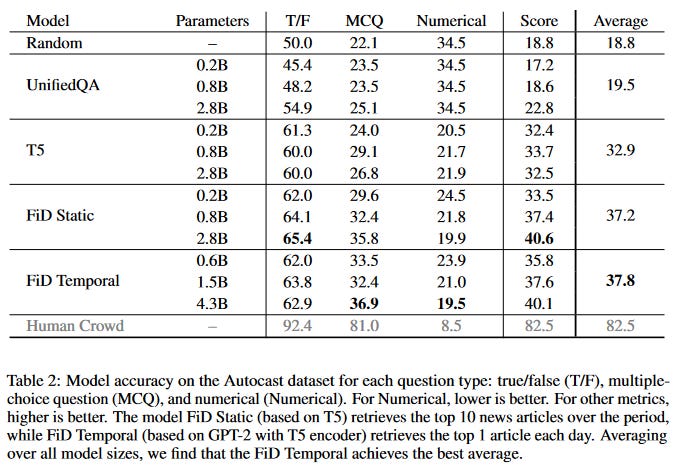
. . . okay, this isn’t very interesting. GPT-2, a very weak obsolete AI, is able to do better than chance, but much worse than humans. I don’t know what I was expecting.
This paper isn’t interesting because the AI did well (it didn’t). It’s interesting as the first foray into quantifying AI forecasting ability. Sometime soon, someone will test how a GPT-3 or GPT-4 sized model does at this task. Probably it will do better. How much better? I’m pretty curious. Can a big enough language model equal humans at forecasting? What would we do with it if it could?
The authors write:
Because it relies on scarce human expertise, forecasting is only used for a small number of questions. This motivates using ML to automate forecasting, e.g. by automating human information retrieval (finding news sources), reasoning (to decide if some evidence bears on a forecast), and quantitative modeling. ML models may also have some advantages over human forecasters. Models can read through text or data much faster than humans and can discern patterns in noisy high-dimensional data that elude humans. When it comes to learning, humans cannot be trained on past data in manner simulating actual forecasting (e.g. How likely was the Soviet Union’s collapse from the viewpoint of 1980?) because they know the outcomes – but past data can be used for ML models.
The problem with forecasting tournaments is that there are only so many superforecasters in the world, and you can’t make them spend a lot of time considering every question you’re interested in. Real money prediction markets try to solve this by creating an incentive to participate in them, but they’re mostly illegal. Good AI forecasters would solve this problem and let forecasting scale.
You can access their dataset here. The authors were originally planning to host a competition to see who could create the best AI forecaster, but due to financial constraints they’ll be running only a reduced version. You can read more about the semi-competition here.
Metaculus Looking Good
Two new reports say nice things about Metaculus’ accuracy.
Vasco Grilo finds it’s much better than low information priors. A simple low-information prior is a coin flip - betting 50% on all yes-no questions. But you can do better: if only 16% of previous Metaculus predictions on politics have resolved true (maybe because question-makers like asking about outlandish possibilities), you can bet 16% chance for the next politics question. Vasco tries some things a little more sophisticated than that, but he finds Metaculus always beats the prior. We should expect that - expert opinion is better than random guessing - but it’s always good to be sure.
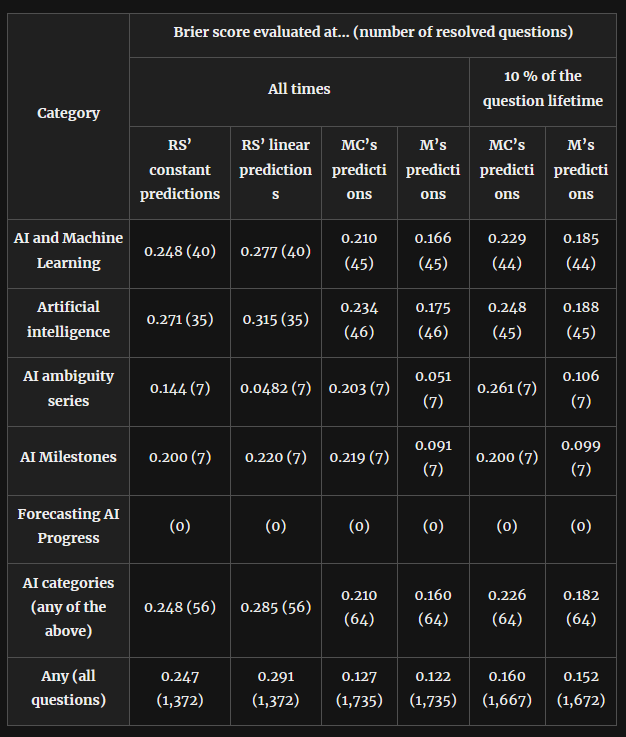 RS is one low information prior. MC is the average forecast. M is the fancy weighted forecast.
RS is one low information prior. MC is the average forecast. M is the fancy weighted forecast.
This also lets us compare how accurate forecasts are in different categories. For example, we see here that AI forecasts have less of an advantage over low-information priors than the average, suggesting that this field is especially tough to predict. But there’s still an advantage. Next time someone tries to tell you that AI is IMPOSSIBLE TO PREDICT and ABSOLUTELY ANYTHING CAN HAPPEN, tell them that actually forecasters achieved a Brier score of 0.160 in AI predictions when guessing the low-information prior would only have given them 0.248.
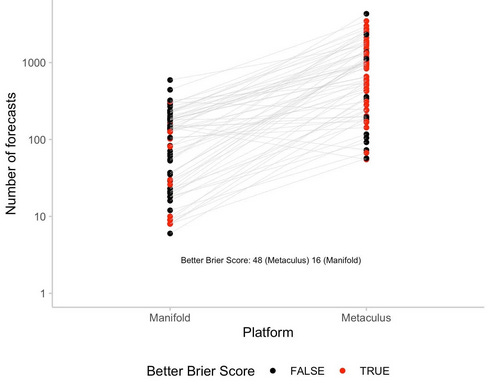
Nikos Bosse compares Metaculus’ performance to its “competitor” Manifold Markets, and finds that overall Metaculus was more accurate:
The mean Brier score was 0.084 for Metaculus and 0.107 for Manifold. This difference was significant using a paired test. Metaculus was ahead of Manifold on 75% of the questions (48 out of 64).
Does this mean that forecasting tournaments are better than prediction markets? Some past studies have provided very tentative evidence in that direction, but this one probably doesn’t - many more people use Metaculus than Manifold, and Nikos didn’t control for number of forecasters.

Nikos also gives us this beautiful graph showing how forecasts on the two platforms track each other (click to expand):
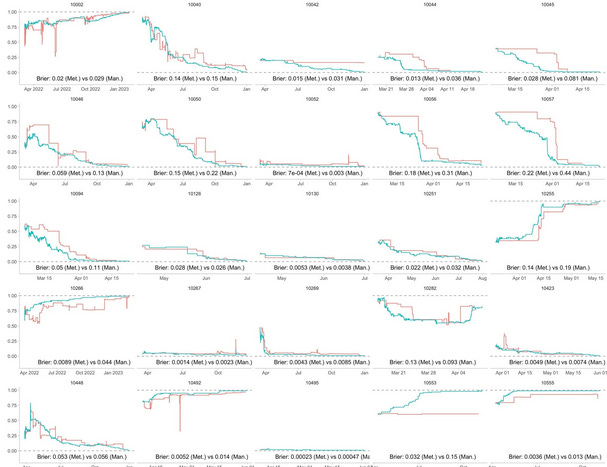
He concludes:
If I were an ambitious user on Manifold and had a free weekend to spend, I would sure as hell start coding up a bot that just trades the Metaculus community prediction on Manifold.
This Month In The Markets
This was the forecast I found myself most interested in this month, and it seems like Manifold has a strong opinion.
The drop a few days ago was when Sam Altman said OpenAI wasn’t currently training GPT-5 and “won’t for some time”. Apparently forecasters don’t expect them to take too long a break.
We’ve talked before about LLMs playing chess; they can sort of do it, but they’re not very good yet. The market thinks 34% chance they’ll get much better in the next five years; I think my estimate is lower.
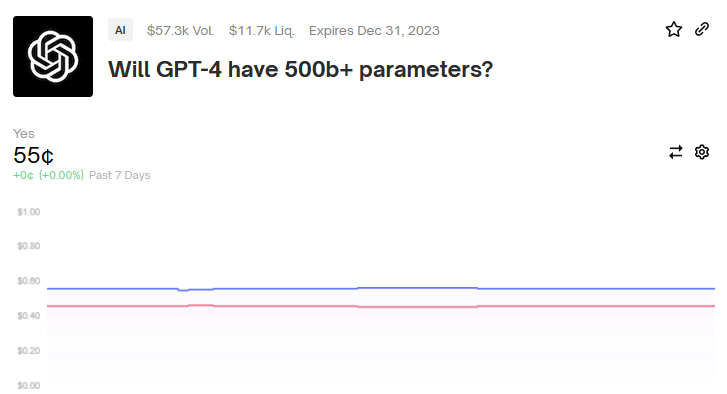
Polymarket is dipping its toes into AI forecasting. This particular one is off to a tough start: GPT-4 came out a month or so after this market was launched, but OpenAI hasn’t said how many parameters it has. You can see all open AI questions (currently just three) here. Also on Polymarket:

Manifold is about the same on the same question. Metaculus’s fancy date prediction system lets them be more specific:
. . . and also seems pretty sure it will be late this year.
Remember when Elon Musk said he would step down as CEO of Twitter? You can see that at the December 2022 mark here - looks like some people made a lot of money buying the dip.
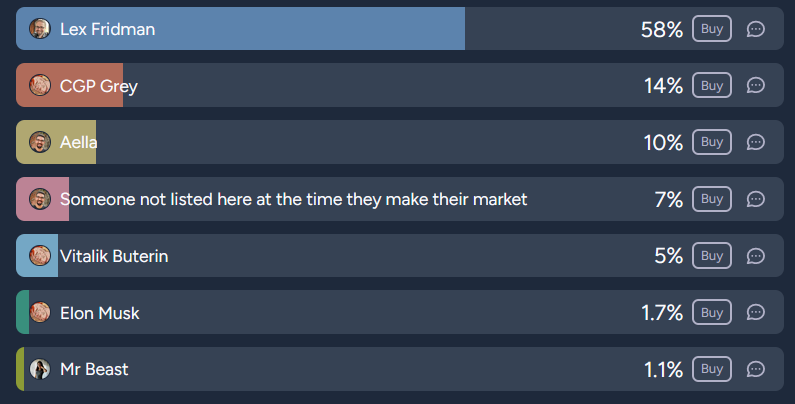
I think of this question as tracking the rise of interest in prediction markets among sci/tech celebrities. Podcaster Lex Fridman (2.7 million Twitter followers) joined Manifold and bet M$100 on himself, causing his shares to soar (they are now worth M$188). He still has not created a market.
This is my Long Bet with Samo Burja - the resolution criteria are slightly different, but close enough to make me feel a little more confident I’m on the right side.
Shorts
1:Metaculus announces Conditional Pairs, where you can create questions that explore the relationship between two events, eg “if the US does/doesn’t default on its debt, will a Democrat win the 2024 election?”
2: Nuno Sempere: Tracking The Money Flows In Forecasting. EG Metaculus runs off of ~$6M in grants; Kalshi has $30M in VC funding. Gnosis, a crypto protocol that never went anywhere, apparently had a $230M market cap at one point, but this is probably some kind of fake crypto valuation trick.
4: Which is better - just looking at the few best forecasters, or fully using the wisdom of crowds? Nikos says it’s the crowds.