The Extinction Tournament
This month’s big news in forecasting: the Forecasting Research Institute has released the results of the Existential Risk Persuasion Tournament (XPT). XPT was supposed to use cutting-edge forecasting techniques to develop consensus estimates of the danger from various global risks like climate change, nuclear war, etc.
The plan was: get domain experts (eg climatologists, nuclear policy experts) and superforecasters (people with a proven track record of making very good predictions) in the same room. Have them talk to each other. Use team-based competition with monetary prizes to incentivize accurate answers. Between the domain experts’ knowledge and the superforecasters’ prediction-making ability, they should be able to converge on good predictions.
They didn’t. In most risk categories, the domain experts predicted higher chances of doom than the superforecasters. No amount of discussion could change minds on either side.
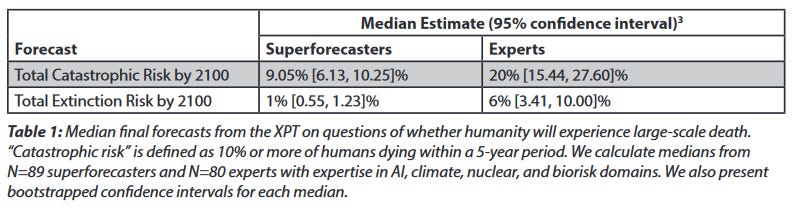
The tournament asked about two categories of global disaster. “Catastrophe” meant an event that killed >10% of the the population within five years. It’s unclear whether anything in recorded history would qualify; Genghis Khan’s hordes and the Black Plague each killed about 20% of the global population, but both events were spread out over a few decades.
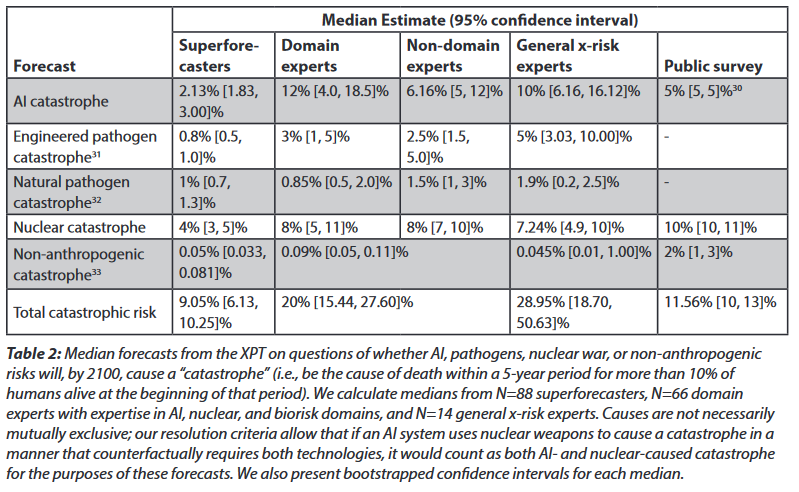
“Extinction” meant reducing total human population below 5,000 (it didn’t require literal extinction). This is very hard! Nuclear war is very unlikely to do this; people in bunkers or remote islands would survive at least the original blasts, and probably any ensuing winter. Even the worst pandemic might not get every remote island or uncontacted Amazonian tribe. Participants assigned the highest literal-extinction risk to AI, maybe because it can deliberately hunt down survivors.

You might notice that all of these numbers are pretty low! I’ve previously said I thought there was a 33% chance of AI extinction alone (and lots of people are higher than me). Existential risk expert Toby Ord estimated a 16% total chance of extinction by 2100, which is 16x higher than these superforecasters and 2.5x higher than these domain experts.
In some sense, this is great news. These kinds of expert + superforecasting tournaments seem trustworthy. Should we update our risk of human extinction downward?
Cancelling The Apocalypse?
It’s weird that there’s so much difference between experts and superforecasters, and awkward for me that both groups are so far away from my own estimates and those of people I trust (like Toby). Is there any reason to doubt the results?
Were the incentives bad?
The subreddit speculates about this - after all, you can’t get paid, or congratulated, or given a trophy, if the world goes extinct. Does that bias superforecasters - who are used to participating in prediction markets and tournaments - downward? What about domain experts, who might be subconsciously optimizing for prestige and reputation?
This tournament tried to control for that in a few ways.
First, most of the monetary incentives were for things other than predicting extinction. There were incentives for making good arguments that persuaded other participants, for correctly predicting intermediate steps to extinction (for example, a small pandemic, or a limited nuclear exchange), or for correctly guessing what other people would guess (this technique, called “reciprocal scoring”, has been validated in past experiments).
Second, this wasn’t really an incentive-based prediction market. Although they kept a few incentives as described above, it was mostly about asking people who had previously demonstrated good predictive accuracy to give their honest impressions. At some point you just have to trust that, absent incentives either way, reasonable people with good track records can be smart and honest.
Third, a lot of the probabilities here were pretty low. For example, the superforecasters got an 0.4% probability of AI-based extinction, compared to the domain experts’ 3%. At these levels it’s probably not worth optimizing your answers super-carefully to get a tiny amount of extra money or credibility. If it’s the year 2100, and we didn’t die from AI, who was right - the people who said there was a 3% chance, or the people who said there was an 0.4% chance? Everyone in this tournament was smart enough to realize that survival in one timeline wouldn’t provide much evidence either way.
As tempting as it is to dismiss this surprising result with an appeal to the incentive structure, we’re not going to escape that easily.
Were the forecasters stupid?
Aside from the implausibility of dozens of top superforecasters and domain experts being dumb, both groups got easy questions right.
The bio-risks questions are a good benchmark here:
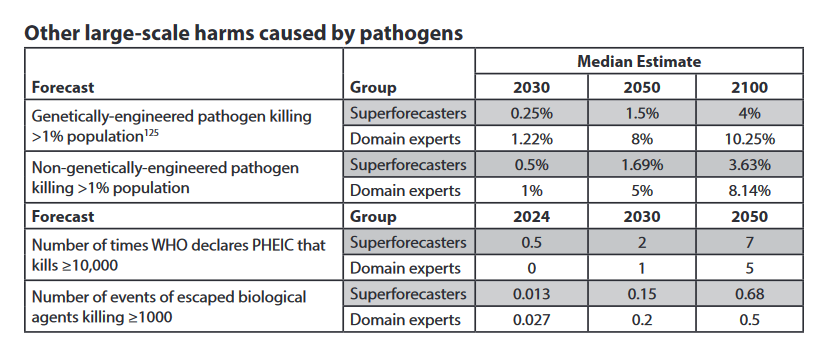
There are centuries’ worth of data on non-genetically-engineered plagues to give us base rates; these give us a base rate of ~25% per century = 20% between now and 2100. But we have better epidemiology and medicine than most of the centuries in our dataset. The experts said 8% chance and the superforecasters said 4% chance, and both of those seem like reasonable interpretations of the historical data to me.
The “WHO declares emergency” question is even easier - just look at how often it’s done that in the past and extrapolate forward. Both superforecasters and experts mostly did that.
Likewise, lots of scientists have put a lot of work into modeling the climate, there aren’t many surprises there, and everyone basically agreed on the extent of global warming:
![]()
Wherever there was clear past data, both superforecasters and experts were able to use it correctly and get similar results. It was only when they started talking about things that had never happened before - global nuclear war, bioengineered pandemics, and AI - that they started disagreeing.
Were the participants out of their depth?
Peter McCluskey, one of the more-AI-concerned superforecasters in the tournament, wrote about his experience on Less Wrong. Quoting liberally:
I signed up as a superforecaster. My impression was that I knew as much about AI risk as any of the subject matter experts with whom I interacted (the tournament was divided up so that I was only aware of a small fraction of the 169 participants).
I didn’t notice anyone with substantial expertise in machine learning. Experts were apparently chosen based on having some sort of respectable publication related to AI, nuclear, climate, or biological catastrophic risks. Those experts were more competent, in one of those fields, than news media pundits or politicians. I.e. they’re likely to be more accurate than random guesses. But maybe not by a large margin […]
The persuasion seemed to be spread too thinly over 59 questions. In hindsight, I would have preferred to focus on core cruxes, such as when AGI would become dangerous if not aligned, and how suddenly AGI would transition from human levels to superhuman levels. That would have required ignoring the vast majority of those 59 questions during the persuasion stages. But the organizers asked us to focus on at least 15 questions that we were each assigned, and encouraged us to spread our attention to even more of the questions […]
Many superforecasters suspected that recent progress in AI was the same kind of hype that led to prior disappointments with AI. I didn’t find a way to get them to look closely enough to understand why I disagreed.
My main success in that area was with someone who thought there was a big mystery about how an AI could understand causality. I pointed him to Pearl, which led him to imagine that problem might be solvable. But he likely had other similar cruxes which he didn’t get around to describing.
That left us with large disagreements about whether AI will have a big impact this century.
I’m guessing that something like half of that was due to a large disagreement about how powerful AI will be this century.
I find it easy to understand how someone who gets their information about AI from news headlines, or from laymen-oriented academic reports, would see a fair steady pattern of AI being overhyped for 75 years, with it always looking like AI was about 30 years in the future. It’s unusual for an industry to quickly switch from decades of overstating progress, to underhyping progress. Yet that’s what I’m saying has happened.
I’ve been spending enough time on LessWrong that I mostly forgot the existence of smart people who thought recent AI advances were mostly hype. I was unprepared to explain why I thought AI was underhyped in 2022.
Today, I can point to evidence that OpenAI is devoting almost as much effort into suppressing abilities (e.g. napalm recipes and privacy violations) as it devotes to making AIs powerful. But in 2022, I had much less evidence that I could reasonably articulate.
What I wanted was a way to quantify what fraction of human cognition has been superseded by the most general-purpose AI at any given time. My impression is that that has risen from under 1% a decade ago, to somewhere around 10% in 2022, with a growth rate that looks faster than linear. I’ve failed so far at translating those impressions into solid evidence.
Skeptics pointed to memories of other technologies that had less impact (e.g. on GDP growth) than predicted (the internet). That generates a presumption that the people who predict the biggest effects from a new technology tend to be wrong.
> Superforecasters’ doubts about AI risk relative to the experts isn’t primarily driven by an expectation of another “AI winter” where technical progress slows. … That said, views on the likelihood of artificial general intelligence (AGI) do seem important: in the postmortem survey, conducted in the months following the tournament, we asked several conditional forecasting questions. The median superforecaster’s unconditional forecast of AI-driven extinction by 2100 was 0.38%. When we asked them to forecast again, conditional on AGI coming into existence by 2070, that figure rose to 1%. There was also little or no separation between the groups on the three questions about 2030 performance on AI benchmarks (MATH, Massive Multitask Language Understanding, QuALITY).
This suggests that a good deal of the disagreement is over whether measures of progress represent optimization for narrow tasks, versus symptoms of more general intelligence.
The “won’t understand causality” and “what if it’s all hype” objections really don’t impress me. Many of the people in this tournament hadn’t really encountered arguments about AI extinction before (potentially including the “AI experts” if they were just eg people who make robot arms or something), and a couple of months of back and forth discussion in the middle of a dozen other questions probably isn’t enough for even a smart person to wrap their brain around the topic.
Was this tournament done so long ago that it has been outpaced by recent events?
The tournament was conducted in summer 2022. This was before ChatGPT, let alone GPT-4. The conversation around AI noticeably changed pitch after these two releases. Maybe that affected the results?
In fact, the participants have already been caught flat-footed on one question:
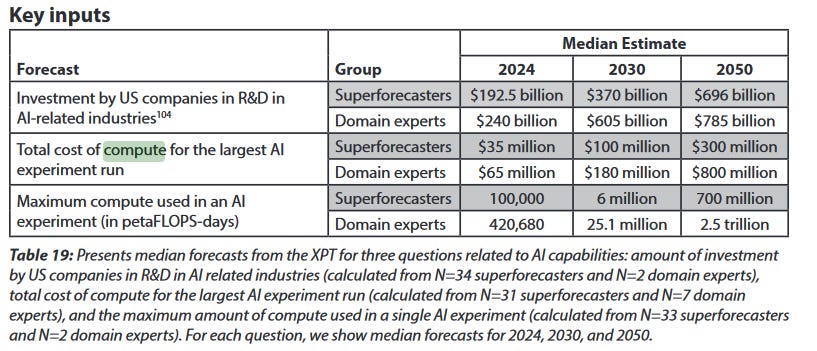
A recent leak suggested that the cost of training GPT-4 was $63 million, which is already higher than the superforecasters’ median estimate of $35 million by 2024 has already been proven incorrect. I don’t know how many petaFLOP-days were involved in GPT-4, but maybe that one is already off also.
There was another question on when an AI would pass a Turing Test. The superforecasters guessed 2060, the domain experts 2045. GPT-4 hasn’t quite passed the exact Turing Test described in the study, but it seems very close, so much so that we seem on track to pass it by the 2030s. Once again the experts look better than the superforecasters.
So is it possible that we, in 2023, now have so much better insight into AI than the 2022 forecasters that we can throw out their results?
We could investigate this by looking at Metaculus, a forecasting site that’s probably comparably advanced to this tournament. They have a question suspiciously similar to XPT’s global catastrophe framing:

In summer 2022, the Metaculus estimate was 30%, compared to the XPT superforecasters’ 9% (why the difference? maybe because Metaculus is especially popular with x-risk-pilled rationalists). Since then it’s gone up to 38%. Over the same period, Metaculus estimates of AI catastrophe risk went from 6% to 15%.
If the XPT superforecasters’ probabilities rose linearly by the same factor as Metaculus forecasters’, they might be willing to update total global catastrophe risk to 11% and AI catastrophe risk to 5%.
But the main thing we’ve updated on since 2022 is that AI might be sooner. But most people in the tournament already agreed we would get AGI by 2100. The main disagreement was over whether it would cause a catastrophe once we got it. You could argue that getting it sooner increases that risk, since we’ll have less time to work on alignment. But I would be surprised if the kind of people saying the risk of AI extinction is 0.4% are thinking about arguments like that. So maybe we shouldn’t expect much change.
FRI called back a few XPT forecasters in May 2023 to see if any of them wanted to change their minds, but they mostly didn’t.
Overall
I don’t think this was just a problem of the incentives being bad or the forecasters being stupid. This is a real, strong disagreement. We may be able to slightly increase their forecast based on recent events, but this would only change the estimate a little.
Breaking Down The AI Estimate
How did the forecasters arrive at their AI estimate? What were the cruxes between the people who thought AI was very dangerous, and the people who thought it wasn’t?
You can think of AI extinction as happening in a series of steps:
-
We get human-level AI by 2100.
-
The AI is misaligned and wants to kill all humans
-
It succeeds at killing all humans.
This isn’t a perfect breakdown. Steps 2 and 3 are complicated: some early AIs will be misaligned but it won’t be a problem because they’re too weak to hurt us (ChaosGPT is already misaligned)! But if we define (2) as “the first AI capable of killing all humans”, then (3) is 100% by definition. Still, there ought to be some decomposition like this. Where do I and the superforecasters part ways?
Question 51 asks when we will have AGI (the resolution criteria are that whatever Nick Bostrom says goes).
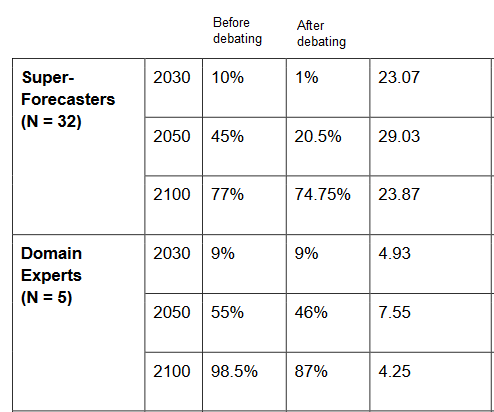
Everyone agrees it’s pretty likely we’ll have AGI (as per Bostrom) by 2100, although the domain experts are a little more convinced than the superforecasters.
There was no question about when or whether we’ll have superintelligence. Metaculus thinks superintelligence will come very shortly after human-level intelligence, and this is the conclusion of the best models and analyses I’ve seen as well. Still, I don’t know if the superforecasters here also believed this.
At this point I’ve kind of exhausted the information I have from XPT, so I’m going to switch to Metaculus and hope it’s a good enough window into forecasters’ thought processes to transfer over. Metaculus wasn’t really built for this and I have to fudge a lot of things, but based on this, this, and this question, plus this synthesis, here’s my interpretation of what they’re thinking:
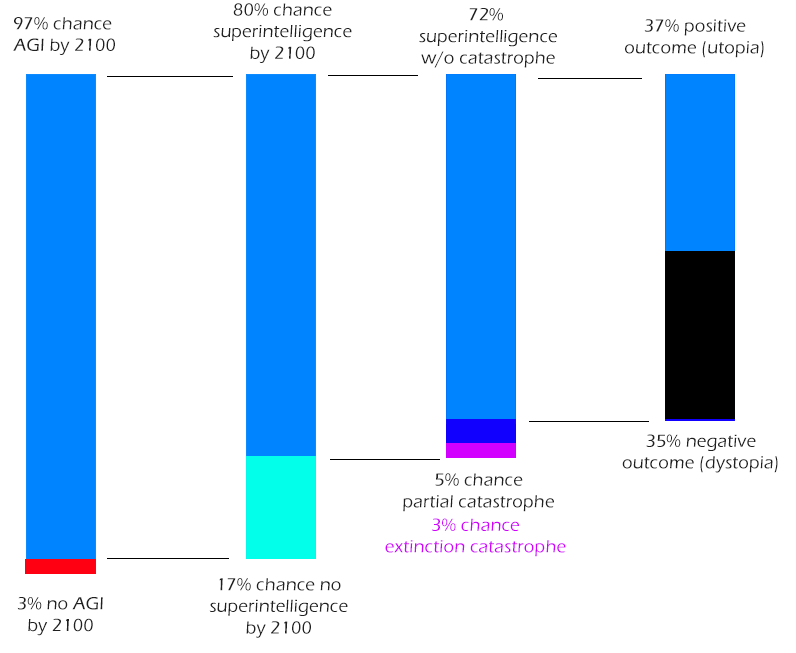
Most of them expect superintelligence to happen and not cause a giant catastrophe, although there is a much higher chance it just goes vaguely badly somehow and produces a society which is bad to live in. This last part is an assumption from many other conditional probabilities plus this question and probably shouldn’t be taken too seriously.
Eyeballing the XPT answers, I think they split more like 80-20 on the AGI by 2100 question, I would expect them to split more like 50-50 on the superintelligence-conditional-on-AGI question, and that’s enough to explain the decreased risk of AGI catastrophe without necessarily bringing in more optimistic beliefs about alignment. It’s not enough to explain the decreased risk of extinction, so the XPT forecasters must believe there’s a higher chance AGI kills many people but not everyone. This could either be because humans fight a war with AGI and win, because AGI causes an “unintentional” catastrophe without being agentic enough to finish the job (eg helps terrorists build a bioweapon), or because AGI defeats humans but lets them continue existing in some form.
Final Thoughts: Athanasius Contra Mundum
Are you allowed to look at a poll of all the world’s top experts plus the superforecasters who have been right most often before, correctly incentivized and aggregated using cutting-edge techniques, and say “yeah, okay, but I disagree”?

There’s been a lot of discussion about this comic and the ideas behind it recently. Can ordinary people disagree with “the experts”? If so, when and how? My usual answers are that this is sometimes permissible: sometimes because sometimes official expert bodies are operating under bad incentive constraints, other times because the people involved don’t understand statistics/rationality/predictions very well.
This study could have been deliberately designed to make me sweat. It was a combination of well-incentivized experts with no ulterior motives plus masters of statistics/rationality/predictions. All of my usual arguments have been stripped away. I think there’s a 33% chance of AI extinction, but this tournament estimated 0.3 - 5%. Should I be forced to update?
This is a hard question, and got me thinking about what “forced to update” even means.
The Inside View Theory Of Updating is that you consult the mysterious lobe of your brain that handles these kinds of things and ask it what it thinks. If it returns a vague feeling of about 33% certainty, then your probability is 33%. You can feed that brain lobe statements like “by the way, you know that all of the top experts and superforecasters and so on think this will definitely not happen, right?” and then it will do mysterious brain things, and at the end of those mysterious brain things it will still feel about 33% certain, and you should still describe yourself as thinking there’s a 33% chance.
The Outside View Theory is more like - you think about all the people who disagree with the experts. There are those people who think the moon landing was fake, and the experts tell them they’re wrong, and they refuse to update, and you think that’s a really bad decision. There are those people who think COVID vaccines don’t work, and ditto. When you think of those people, you wish they would have the sense to just ignore whatever their mysterious reasoning lobes are telling them and trust the experts instead. But then it seems kind of hypocritical if you don’t also defer to the experts on when it’s your turn to disagree with them. By “hypocritical” I mean both a sort of epistemic failure, where you’re asserting a correct reasoning procedure but then refusing to follow it - and also a sort of moral failure, where your wish that they would change their minds won’t be honored by the Gods of Acausal Trade unless you also change your mind.
You can compromise between these views. One compromise is that you should meditate very hard on the Outside View and see if it makes your mysterious brain lobe update its probability. If it doesn’t, uh, meditate harder, I guess. Another compromise is to agree to generally act based on the Outside View in order to be a good citizen, while keeping your Inside View estimate intact so that everyone else doesn’t double-update on your opinions or cause weird feedback loops and cascades.
The strongest consideration pushing me towards Inside View on this topic is Peter McCluskey’s account linked earlier. When I think of vague “experts” applying vague “expertise” to the problem, I feel tempted to update. But when I hear their actual arguments, and they’re the same dumb arguments as all the other people I roll my eyes at, it’s harder to take them seriously.
Still, the considerations for Outside View don’t completely lack compelling power, so I suppose I update to more like 20 - 25% chance. This is still pretty far from the top tournament-justifiable probability of 5%, or even a tournament-justifiable-updated-by-recent-events probability of 5-10%. But it’s the lowest I can make the mysterious-number-generating lobe of my brain go before it threatens to go on strike in protest.
I’m heartened to remember that the superforecasters and domain experts in this study did the same. Confronted with the fact that domain experts/superforecasters had different estimates than they did, superforecasters/domain experts refused to update, and ended an order of magnitude away from each other. That seems like an endorsement of non-updating from superforecasters and domain experts! And who am I to disagree with such luminaries? It would be like trying to take over a difficult plane-landing from a pilot! Far better to continue stubbornly disagreeing with domain experts and superforecasters, just like my role models the superforecasters and domain experts do.
[XPT co-author Philip Tetlock will be atthe ACX meetup this Sunday. If you have any questions, maybe he can answer them for you!]