Who Predicted 2022?
Last year saw surging inflation, a Russian invasion of Ukraine, and a surprise victory for Democrats in the US Senate. Pundits, politicians, and economists were caught flat-footed by these developments. Did anyone get them right?
In a very technical sense, the single person who predicted 2022 most accurately was a 20-something data scientist at Amazon’s forecasting division.
I know this because last January, along with amateur statisticians Sam Marks and Eric Neyman, I solicited predictions from 508 people. This wasn’t a very creative or free-form exercise - contest participants assigned percentage chances to 71 yes-or-no questions, like “Will Russia invade Ukraine?” or “Will the Dow end the year above 35000?” The whole thing was a bit hokey and constrained - Nassim Taleb wouldn’t be amused - but it had the great advantage of allowing objective scoring.
 Sample questions.
Sample questions.
Our goal wasn’t just to identify good predictors. It was to replicate previous findings about the nature of prediction. Are some people really “superforecasters” who do better than everyone else? Is there a “wisdom of crowds”? Does the Efficient Markets Hypothesis mean that prediction markets should beat individuals? Armed with 508 people’s predictions, can we do math to them until we know more about the future (probabilistically, of course) than any ordinary mortal?
After 2022 ended, Sam and Eric used a technique called log-loss scoring to grade everyone’s probability estimates. Lower scores are better. The details are hard to explain, but for our contest, guessing 50% for everything would give a score of 40.21, and complete omniscience would give a perfect score of 0.
Here’s how the contest went:
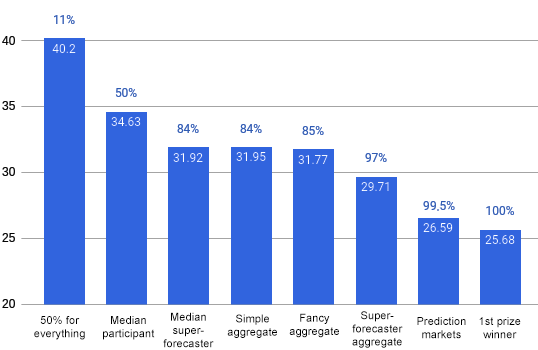 Note truncated vertical axis
Note truncated vertical axis
As mentioned above: guessing 50% corresponds to a score of 40.2. This would have put you in the eleventh percentile (yes, 11% of participants did worse than chance).
Philip Tetlock and his team have identified “superforecasters” - people who seem to do surprisingly well at prediction tasks, again and again. Some of Tetlock’s picks kindly agreed to participate in this contest and let me test them. The median superforecaster outscored 84% of other participants.
The “wisdom of crowds” hypothesis says that averaging many ordinary people’s predictions produces a “smoothed-out” prediction at least as good as experts. That proved true here. An aggregate created by averaging all 508 participants’ guesses scored at the 84th percentile, equaling superforecaster performance.
There are fancy ways to adjust people’s predictions before aggregating them that outperformed simple averaging in the previous experiments. Eric tried one of these methods, and it scored at the 85th percentile, barely better than the simple average.
Crowds can beat smart people, but crowds of smart people do best of all. The aggregate of the 12 participating superforecasters scored at the 97th percentile.
Prediction markets did extraordinarily well during this competition, scoring at the 99.5th percentile - ie they beat 506 of the 508 participants, plus all other forms of aggregation. But this is an unfair comparison: our participants were only allowed to spend five minutes max researching each question, but we couldn’t control prediction market participants; they spent however long they wanted. That means prediction markets’ victory doesn’t necessarily mean they’re better than other aggregation methods - it might just mean that people who can do lots of research beat people who do less research.2 Next year’s contest will have some participants who do more research, and hopefully provide a fairer test.
The single best forecaster of our 508 participants got a score of 25.68. That doesn’t necessarily mean he’s smarter than aggregates and prediction markets. There were 508 entries, ie 508 lottery tickets to outperform the markets by coincidence. Most likely he won by a combination of skill and luck. Still, this is an outstanding performance, and must have taken extraordinary skill, regardless of how much luck was involved.
And The Winners Are . . .
I planned to recognize the top five of these 508 entries. After I sent out prize announcement emails, a participant pointed out flaws in our resolution criteria3. We decided to give prizes to people who won under either resolution method. 1st and 2nd place didn’t change, but 3rd, 4th, and 5th did - so seven people placed in the top five spots. They are:
-
1st: Ryan Kupyn. Ryan is a forecasting researcher at Amazon. His main hobby outside of work is designing walking tours for different Los Angeles neighborhoods. He asks me to include his “meet-me email address” coffee@ryankupyn.com, saying “I love to meet new people and talk about careers, ML, their best breakfast recipes and anything else.”4
-
2nd: Thomas S. Thomas lives in Germany. He works in finance with a background
in physics. He says he has never done forecasting before, but trades occasionally on prediction markets (without much success).
-
3rd: PPV. PPV is a high school dropout, manual laborer, “psychology enthusiast”, and occasional trader. He has never done forecasting before, and describes his strategy as “anchoring to predictions given in the list when in doubt, correcting for what I saw as a lot of recency bias, and skipping all the questions I would clearly be average or worse at. I skipped a lot of them.”
-
3rd: Skerry. Skerry works in finance, with a background in economics. He’s participated in forecasting before, including the Good Judgment Project and a small amount of prediction market trading.
-
4th: Andreas H. Andreas describes himself as a student of geography who splits his time between Canada and Germany. He is also interested in transportation, politics, and economics. His Twitter is https://twitter.com/AH23923011
-
4th: Johan Kjeldgaard-Pedersen. Johan** “runs the Copenhagen office of the boutique consulting firm data2impact, which offers pretty much any number crunching service imaginable, including forecasting.”
-
5th: Haakon Riekeles is an economist and a member of the city council of Oslo, Norway, where he hopes to promote a more YIMBY attitude to development. He says: “I haven’t done any forecasting [before], but I’ve done a bit of betting on elections and political outcomes and so far I’ve beaten the bookies.”
Here are some other interesting people who did exceptionally well and scored near the top of the 508 entries:
-
7th: Ezra Karger. Ezra is research director at the Forecasting Research Institute. This contest is an amateurish retreading of work that FRI’s Philip Tetlock already did much more formally years ago, and we feel honored that he entered at all. I’m not sure why it should be the case that forecasting researchers are also excellent forecasters, but Ezra has adequately demonstrated this at least in his own case.
-
8th: Zach Stein-Perlman. Zach entered under the pseudonym “ My expected score is slightly worse than it would be if I always gave my true probabilities. I mention this in case you want to exclude me from analysis for that reason. (The form says “there is no strategic advantage to putting anything other than your honest predictions for each event”, but this is totally false: I don’t care about expected score, just probability of doing very well. If Scott had said to be honest, I would have, but instead he said “The winner will get eternal glory” so I’m lazily* maximizing winning probability. *If the universe was at stake, I would consider other tactics, but it’s not, so I’m just being overconfident” , but I was able to figure out who he was from the email address. Zach is a forecaster and research analyst at AI Impacts, a nonprofit (founded by my ex-girlfriend) that tries to predict the future course of AI.
-
11th: John Schilling. John works in aerospace and is one of ACX’s most prolific commenters.
-
20th: Peter Wildeford. Peter is the co-CEO of effective altruist organization Rethink Priorities. He’s also one of the top forecasters on Metaculus. You can hear him discuss his forecasting strategies on the Inside View podcast.
-
25th: Dillon Plunkett.Dillon is a cognitive neuroscientist who studies the ‘language of thought’ at Harvard and Northeastern.
-
54th: Zvi Mowshowitz. Zvi is a former trader and professional Magic player who blogs at Don’t Worry About The Vase. Since he’s one of the only other bloggers interested in forecasting, I often end up pitted against him in forecasting competitions. I always lose, and this won’t be the year that breaks my streak.
And thanks to our question-writers:
-
Matt Yglesias and Vox Future Perfect didn’t officially enter the competition, but we adapted some of their questions (Matt, VFP). For the subset of questions they answered (quick calculation, haven’t double-checked, take with a grain of salt), Matt scored in the 46th percentile, and Future Perfect scored in the 17th. Thanks to both Matt and Vox for (nonconsensually) participating!
-
I (Scott Alexander) did formally enter the contest, and scored in the 54th percentile. I never claimed to be a great forecaster, just a forecasting fanboy.5
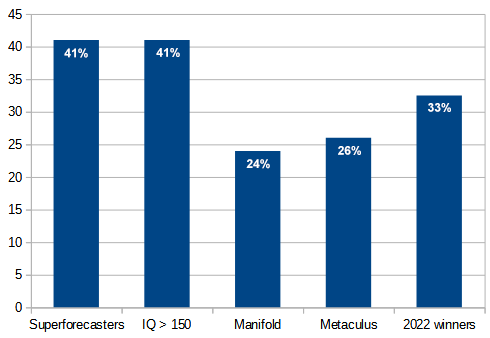
Along with looking at individuals, we also tried to figure out which groups did the best - whether there were any demographic characteristics that reliably predicted good forecasting. Not really. Liberals didn’t outperform conservatives, old people didn’t outperform young people, nothing like that6. Users of the website Less Wrong, which tries to teach a prediction-focused concept of rationality, didn’t significantly outperform others, which disappointed me.
But users with self-reported IQ > 150 may have outperformed everyone else. This result needs many caveats: it was sensitive to cutoff points, self-reported IQs are unreliable, and sample sizes were low. Still, these people did almost as well as superforecasters, an impressive performance.7
Towards 2023: Pushing Back The Veil
Given what we’ve learned, can we predict 2023?
Sam, Eric and I are running a repeat version of the contest for 2023. We have about 3500 entries so far, answering questions like “Will there be a lasting cease-fire in Ukraine?” I’ve peeked at the submissions, and - spoiler - everyone disagrees.
This is the human condition. The future is murky. Nobody knows for sure what will happen. Get 3500 people, and there will be 3500 views.
What’s new is that we have methods that can, with high levels of certainty, mediate these disagreements. Last year, superforecaster aggregation beat 97% of individual predictors. This finding has been replicated in other experiments. Probably it will hold true this year too. By running a simple algorithm on the data I have, I can beat 3400 of these 3500 participants.
Or maybe the prediction market results will hold. One market (Manifold) and another market-like site (Metaculus) are joining the contest this year. If they do as well as last year, they’ll beat all but 15 of the 3500 entries. If things go very well, maybe we’ll discover new ways of aggregating their results that can beat every individual predictor, at least most of the time.
If this seems boring and technical to you, I maintain it should instead sound mystical, maybe even blasphemous. It is not given for humans to see the future. But it’s not impossible to see the future either - for example, I confidently predict that the sun will rise tomorrow. This project is about discovering the limits of that possibility. A 40% vs. 41% chance of a cease-fire in Ukraine next year might feel like a minor difference. But this is the sort of indeterminate portentious future event it feels impossible to know anything about at all, and here we are slightly shaving off layers of uncertainty, one by one. A person who estimates a 99.99999% chance of a cease-fire in Ukraine next year is clearly more wrong than someone who says a 41% chance. Maybe it’s possible to say with confidence that a 41% chance to be better than a 40% chance, and for us to discover this, and to hand it to policy-makers charting plans that rely on knowing what will happen.
 The percent chance of a lasting cease-fire in Ukraine sometime during 2023, according to various groups, sources, and aggregation methods.
The percent chance of a lasting cease-fire in Ukraine sometime during 2023, according to various groups, sources, and aggregation methods.
None of these aggregation methods are the most accurate source of forecasts on a Ukraine cease-fire - that would be Putin and Zelenskyy, who could have secret plans they haven’t announced. These methods might not even be the most accurate public source - maybe that’s someone with an International Relations PhD who’s studied the region their whole life.
But we talk about fuel efficiency for cars. This is about knowledge efficiency. Given certain resources - the information about Ukraine available to the general public, a few minutes of reflection - how much accuracy can we wring out of those? There must be some limit. But we haven’t found it yet. And every new algorithm pushes back the veil a little bit further, very slightly expanding what mortals may know about what is to come.
If you entered the contest, you can check your score using this website.
Special thanks to Sam Marks and Eric Neyman for running the contest.
Sam is nominally a math grad student at Harvard, but actually spends most of his time thinking about AI alignment and developing the educational programming for the Harvard and MIT AI safety student groups.
Eric is nominally a grad student at Columbia studying algorithms for elicitation and aggregation of knowledge, but he’s on a leave of absence to do research in AI alignment. Eric blogs at Unexpected Values, and you can read some of his more formal work on prediction aggregation here.
You can access the anonymized contest dataset here.
For complex forecasting problems, I try to explicitly model the processes at work and backtest on as much data as possible, bringing in domain experts to validate my assumptions. But beyond that, I don’t have a universal methodology.
There are probably a few factors that I think contributed to me winning the competition:
I tried to deliberately structure my answers to maximize my probability of winning, rather than maximize the probability of each individual answer being correct. Because there could be only one winner, my model of win probability was (probability of predictions being accurate) / (local density of competitors with similar predictions to me). This is a different approach than what it’d try for a standard prediction market - the analogy I’d use is that it’s the inverse of a Keynesian beauty contest, where I’m trying to find “underrated” outcomes that specifically won’t be predicted by many other people.
I thought specifically that people were underrating the likelihood that Russia would invade Ukraine, and that this fact would have correlated impacts on a bunch of other questions. In particular, I thought an invasion would lead to big deviations from the consensus outcomes for inflation and asset prices (including crypto).
Because of this, I put predictions for these questions that were higher than I’d expect in isolation - in effect, I was aiming for a high-variance (or leveraged) outcome, since last place was no worse than second. In a counterfactual world where Russia didn’t invade Ukraine, I think my predictions would have been much worse than the average entrant.
I didn’t do any research at all when answering the questions - in my experience I have a tough time generating better predictions than my baseline with only a few minutes of research, as recency bias typically outweighs the benefit of adding new information to my mental model.
Sheer luck - for instance, I’d talked to some people from the Philippines about Bongbong Marcos a few days before entering the competition, and was surprised by how enthusiastic they were about him. I suspect this made me more bullish on his chances of being elected than most of the other entrants.
Skerry wrote:
Aside from Russia/Ukraine, Roe being overturned, and Twitter drama, which seem to total at most three of the questions in the contest, it seems like 2022 was a less dramatic year than people were speculating in January/early February. I probably put more weight on “no change” or “business as usual” than most, and that worked out well this time around.
Johan wrote:
I think that any interesting forecasting requires a holistic/systemic understanding of the thing being forecast, and I have a soft spot for the System Dynamics methodology as taught at MIT Sloan. Best guess as to why I did well in the ACX Prediction Contest is the above plus subscribing to one liberal and one conservative news outlet and reading both regularly. And luck.
Haakon wrote:
My strategy is to trust but verify numbers where you can find them, but think carefully about how they are generated. Furthermore, conventional wisdom probably overestimate the probability of things that are highly salient and vice-versa.
-
This number and the following graph include only the 61 out of 71 questions that we had prediction market estimates for, in order to keep the prediction market results commensurable with the other results. The additional ten questions were added back in before awarding prizes.
-
But Sam and Eric object that prediction markets were also handicapped this year - most of the markets they took their numbers from were very small Manifold markets with only a single-digit number of participants, just a few months after Manifold started existing at all. They say the most likely reason prediction markets did so well was because only the most knowledgeable people will bet on a certain question, whereas our contest encouraged everyone to predict each question (technically you could opt out, but most people didn’t). Plausibly this coming year, when we have multiple big prediction markets for each question, the markets will totally blow away all other participants.
-
Matt Yglesias scored his question “Will Nancy Pelosi announce plans to retire?” as TRUE, but technically she only announced that she would retire as Democratic leader, not as a Congresswoman, so the question is false as written. Vox Future Perfect scored their question “Will the Biden administration set a social cost of carbon at > $100” as PARTIALLY RIGHT, because they announced plans to maybe do this, but they have not done it yet and the question is false as written. We originally resolved “Will a Biden administration Cabinet-level official resign?” as FALSE, but Eric Lander, a science advisor who resigned, was technically Cabinet-level and the question as written is true. These changes didn’t affect headline results much, but they shifted some people up or down a few places, and shifted a few people with very high confidence on these questions up or down a few dozen places.
-
I asked the winners for their forecasting advice. Ryan wrote:
-
But also, I was the first person to enter, everyone else got to see my results, and anyone who chose not to answer a specific question defaulted to my results. This gave other people an advantage over me. This coming year we’ve changed the rules in a way that gives me less of a disadvantage, so we’ll see how I do.
-
Actually, if you analyze raw scores, liberals did outperform conservatives, and old people did outperform young people. But Eric made a strong argument that raw scores were too skewed and we should be comparing percentile ranks instead. That is, some people did extremely badly, so their raw scores could be extreme outliers and unfairly skew the correlations, but nobody can have a percentile rank lower than100th. When you analyze percentile ranks, these effects disappeared.
-
If you analyze raw scores, IQ correlates with score pretty well. But when you analyze percentile ranks, you need to group people into <150 and >150 to see any effect.