Sam Altman Wants $7 Trillion
[All numbers here are very rough and presented in a sloppy way. For the more rigorous versions of this, readTom Davidson, Yafah Edelman, and EpochAI)
I.
Sam Altman wants $7 trillion.
In one sense, this isn’t news. Everyone wants $7 trillion. I want $7 trillion. I’m not going to get it, and Sam Altman probably won’t either.
Still, the media treats this as worthy of comment, and I agree. It’s a useful reminder of what it will take for AI to scale in the coming years.
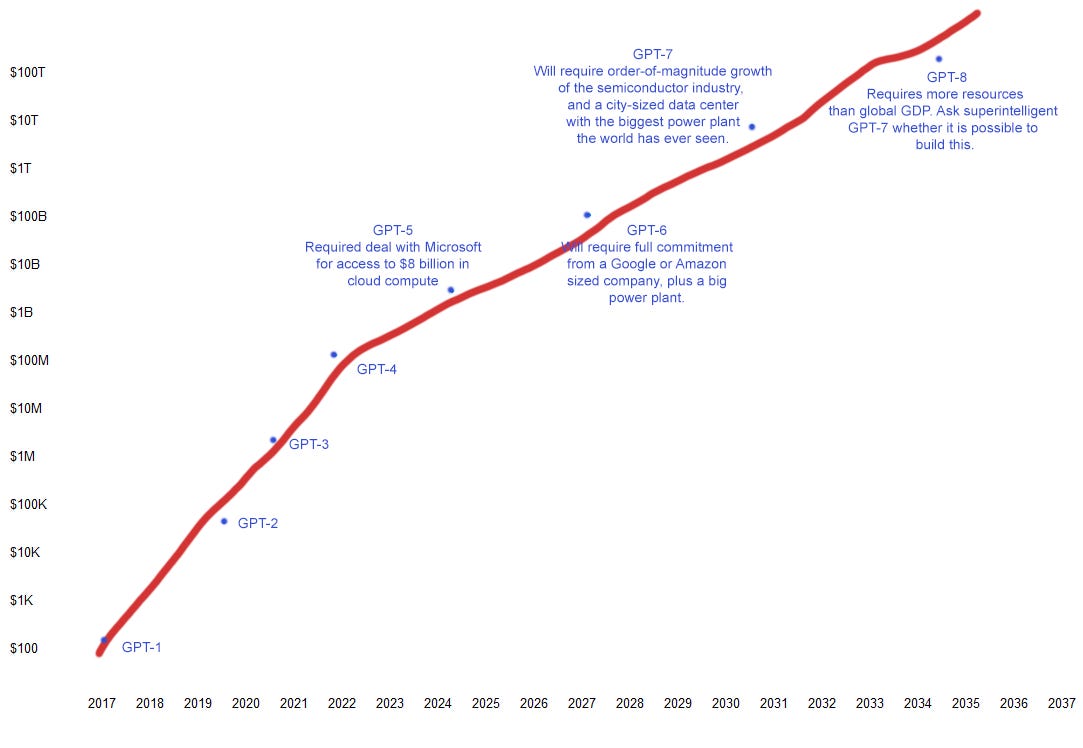
The basic logic: GPT-1 cost approximately nothing to train. GPT-2 cost $40,000. GPT-3 cost $4 million. GPT-4 cost $100 million. Details about GPT-5 are still secret, but one extremely unreliable estimate says $2.5 billion, and this seems the right order of magnitude given the $8 billion that Microsoft gave OpenAI.
So each GPT costs between 25x and 100x the last one. Let’s say 30x on average. That means we can expect GPT-6 to cost $75 billion, and GPT-7 to cost $2 trillion.
(Unless they slap the name “GPT-6” on a model that isn’t a full generation ahead of GPT-5. Consider these numbers to represent models that are eg as far ahead of GPT-4 as GPT-4 was to GPT-3, regardless of how they brand them.)
Let’s try to break that cost down. In a very abstract sense, training an AI takes three things:
-
Compute (ie computing power, hardware, chips)
-
Electricity (to power the compute)
-
Training data
Compute
Compute is measured in floating point operations (FLOPs). GPT-3 took 10^23 FLOPs to train, and GPT-4 plausibly 10^25.
The capacity of all the computers in the world is about 10^21 FLOP/second, so they could train GPT-4 in 10^4 seconds (ie two hours). Since OpenAI has fewer than all the computers in the world, it took them six months. This suggests OpenAI was using about 1/2000th of all the computers in the world during that time.
If we keep our 30x scaling factor, GPT-5 will take 1/70th of all the computers in the world, GPT-6 will take 1/2, and GPT-7 will take 15x as many computers as exist. The computing capacity of the world grows quickly - this source says it doubles every 1.5 years, which means it grows by an order of magnitude every five years, which means these numbers are probably overestimates. If we imagine five years between GPTs, then GPT-6 will actually only need 1/10th of the world’s computers, and GPT-7 will only need 1/3. Still, 1/3 of the world’s computers is a lot.
Probably you can’t get 1/3 of the world’s computers, especially when all the other AI companies want them too. You would need to vastly scale up chip manufacturing.
Energy
GPT-4 took about 50 gigawatt-hours of energy to train. Using our scaling factor of 30x, we expect GPT-5 to need 1,500, GPT-6 to need 45,000, and GPT-7 to need 1.3 million.
Let’s say the training run lasts six months, ie 4,320 hours. That means GPT-6 will need 10 GW - about half the output of the Three Gorges Dam, the biggest power plant in the world. GPT-7 will need fifteen Three Gorges Dams. This isn’t just “the world will need to produce this much power total and you can buy it”. You need the power pretty close to your data center. Your best bet here is either to get an entire pipeline like Nord Stream hooked up to your data center, or else a fusion reactor.
(Sam Altman is working on fusion power, but this seems to be a coincidence. At least, he’s been interested in fusion since at least 2016, which is way too early for him to have known about any of this.)
Training Data
This is the text or images or whatever that the AI reads to understand how its domain works. GPT-3 used 300 billion tokens. GPT-4 used 13 trillion tokens (another source says 6 trillion). This sort of looks like our scaling factor of 30x still kind of holds, but in theory training data is supposed to scale as the square root of compute - so you should expect a scaling factor of 5.5x. That means GPT-5 will need somewhere in the vicinity of 50 trillion tokens, GPT-6 somewhere in the three-digit trillions, and GPT-7 somewhere in the quadrillions.
There isn’t that much text in the whole world. You might be able to get a few trillion more by combining all published books, Facebook messages, tweets, text messages, and emails. You could get some more by adding in all images, videos, and movies, once the AIs learn to understand those. I still don’t think you’re getting to a hundred trillion, let alone a quadrillion.
You could try to make an AI that can learn things with less training data. This ought to be possible, because the human brain learns things without reading all the text in the world. But this is hard and nobody has a great idea how to do it yet.
More promising is synthetic data, where the AI generates data for itself. This sounds like a perpetual motion machine that won’t work, but there are tricks to get around this. For example, you can train a chess AI on synthetic data by making it play against itself a million times. You can train a math AI by having it randomly generate steps to a proof, eventually stumbling across a correct one by chance, automatically detecting the correct proof, and then training on that one. You can train a video game playing AI by having it make random motions, then see which one gets the highest score. In general you can use synthetic data when you don’t know how to create good data, but you do know how to recognize it once it exists (eg the chess AI won the game against itself, the math AI got a correct proof, the video game AI gets a good score). But nobody knows how to do this well for written text yet.
Maybe you can create a smart AI through some combination of text, chess, math, and video games - some humans pursue this curriculum, and it works fine for them, sort of.
This is kind of the odd one out - compute and electricity can be solved with lots of money, but this one might take more of a breakthrough.
Algorithmic Progress
This means “people make breakthroughs and become better at building AI”. It seems to be another one of those things that gives an order of magnitude of progress per five years or so, so I’m revising the estimates above down by a little.
Putting It All Together
GPT-5 might need about 1% the world’s computers, a small power plant’s worth of energy, and a lot of training data.
GPT-6 might need about 10% of the world’s computers, a large power plant’s worth of energy, and more training data than exists. Probably this looks like a town-sized data center attached to a lot of solar panels or a nuclear reactor.
GPT-7 might need all of the world’s computers, a gargantuan power plant beyond any that currently exist, and way more training data than exists. Probably this looks like a city-sized data center attached to a fusion plant.
Building GPT-8 is currently impossible. Even if you solve synthetic data and fusion power, and you take over the whole semiconductor industry, you wouldn’t come close. Your only hope is that GPT-7 is superintelligent and helps you with this, either by telling you how to build AIs for cheap, or by growing the global economy so much that it can fund currently-impossible things.
 Everything about GPTs >5 is a naive projection of existing trends and probably false. Order of magnitude estimates only.
Everything about GPTs >5 is a naive projection of existing trends and probably false. Order of magnitude estimates only.
You might call this “speculative” and “insane”. But if Sam Altman didn’t believe something at least this speculative and insane, he wouldn’t be asking for $7 trillion.
II.
Let’s back up.
GPT-6 will probably cost $75 billion or more. OpenAI can’t afford this. Microsoft or Google could afford it, but it would take a significant fraction (maybe half?) of company resources.
If GPT-5 fails, or is only an incremental improvement, nobody will want to spend $75 billion making GPT-6, and all of this will be moot.
On the other hand, if GPT-5 is close to human-level, and revolutionizes entire industries, and seems poised to start an Industrial-Revolution-level change in human affairs, then $75 billion for the next one will seem like a bargain.
Also, if you’re starting an Industrial Revolution level change in human affairs, maybe things get cheaper. I don’t expect GPT-5 to be good enough that it can make a big contribution to planning for GPT-6. But you’ve got to think of this stepwise. Can it do enough stuff that large projects (like GPT-6, or its associated chip fabs, or its associated power plants) get 10% cheaper? Maybe.
The upshot of this is that we’re looking at an exponential process, like R for a pandemic. If the exponent is > 1, it gets very big very quickly. If the exponent is < 1, it fizzles out.
In this case, if each new generation of AI is exciting enough to inspire more investment, and/or smart enough to decrease the cost of the next generation, then these two factors combined allow the creation of another generation of AIs in a positive feedback loop (R > 1).
But if each new generation of AI isn’t exciting enough to inspire the massive investment required to create the next one, and isn’t smart enough to help bring down the price of the next generation on its own, then at some point nobody is willing to fund more advanced AIs, and the current AI boom fizzles out (R < 1). This doesn’t mean you never hear about AI - people will probably generate amazing AI art and videos and androids and girlfriends and murderbots. It just means that raw intelligence of the biggest models won’t increase as quickly.
Even when R < 1, we still get the bigger models eventually. Chip factories can gradually churn out more chips. Researchers can gradually churn out more algorithmic breakthroughs. If nothing else, you can spend ten years training GPT-7 very slowly. It just means we get human or above-human level AI in the mid-21st century, instead of the early part.
III.
When Sam Altman asks for $7 trillion, I interpret him as wanting to do this process in a centralized, quick, efficient way. One guy builds the chip factories and power plants and has them all nice and ready by the time he needs to train the next big model.
Probably he won’t get his $7 trillion. Then this same process will happen, but slower, more piecemeal, and more decentralized. They’ll come out with GPT-5. If it’s good, someone will want to build GPT-6. Normal capitalism will cause people to gradually increase chip capacity. People will make a lot of GPT-5.1s and GPT-5.2s until finally someone takes the plunge and builds the giant power plant somewhere. All of this will take decades, happen pretty naturally, and no one person or corporation will have a monopoly.
I would be happier with the second situation: the safety perspective here is that we want as much time as we can get to prepare for disruptive AI.
Sam Altman previously endorsed this position! He said that OpenAI’s efforts were good for safety, because you want to avoid compute overhang. That is, you want AI progress to be as gradual as possible, not to progress in sudden jerks. And one way you can keep things gradual is to max out the level of AI you can build with your current chips, and then AI can grow (at worst) as fast as the chip supply, which naturally grows pretty slowly.
… unless you ask for $7 trillion dollars to increase the chip supply in a giant leap as quickly as possible! People who trusted OpenAI’s good nature based on the compute overhang argument are feeling betrayed right now.
My current impression of OpenAI’s multiple contradictory perspectives here is that they are genuinely interested in safety - but only insofar as that’s compatible with scaling up AI as fast as possible. This is far from the worst way that an AI company could be. But it’s not reassuring either.